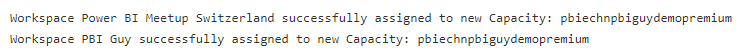Note from PBI Guy: A few weeks ago I had the pleasure to meet Manel Omani, a colleague of mine, who presented a super interesting solution how she’s tracking Power BI Capacity overloaders via Power Automate and notify automatically the Dataset owner. I thought this has to be shared with the Power BI community and asked here to create a blog post about it. Luckily, she agreed and I’m happy to share the result here.
As a Power BI Capacity administrator, have you ever experienced multiple slowdowns and noticed that too late ? This is a very common issue that capacity administrators face when they track and monitor the usage of memory/CPU of the artifacts. Thankfully, in the capacity setting we still have the possibility to set notifications whenever the load reaches x%, or when it exceeds the available capacity. This notifications are helpful to detect the slowdowns early on, but do not really help to highlight which artifact is consuming more resources than the others. To get this information, you need to check it on “the Premium metrics app”.
The idea of this article is to propose ways to combine the Premium metrics app and Power Automate in order to set notification to the owner of the artifact causing slowdowns on the capacity so that they can work on optimizing their data model and prevent future slowdowns.
Overloaders detection on Power BI Premium: the approach
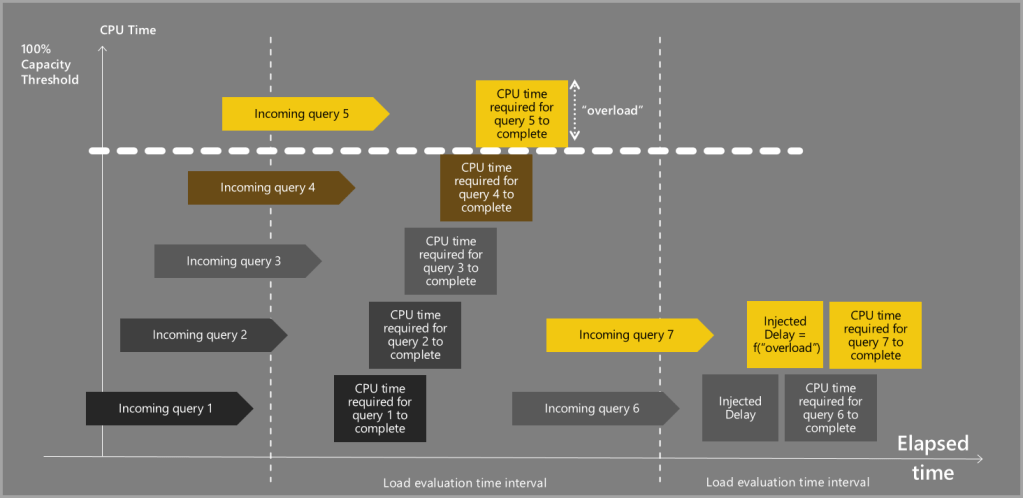
Capacity overload happens when one consumes more CPU in a 30sec interval than what the capacity allows. For instance, if you have a P1 capacity, you can consume 8 cores * 30 sec = 240 sec of CPU time. If you exceed 240 sec CPU time in a 30 sec interval, all the queries that follow with be delayed.
This overload can be detected on the Premium metrics app on the CPU% chart.
And from the Premium metrics app dataset we can run the following DAX query by using DAX Studio to get the list of overloaders IDs:
Keep in mind that your workspace have to be backed up by a capacity to be able to connect with DAX Studio to your Dataset and execute the statement.
This DAX query gives us the list of artifacts that has raised an overload in the last 24 hours. The results are as follows:
This DAX Query is run on the Data Model of the Premium App Monitoring. Please note that this DAX query may need to be changed if the data model of the App Monitoring is updated.
Now that the overloaders are identified, the objective is to get the owner of these artifacts and the details behind the overloading. As the Premium Capacity app does not hold this data, we need to find another approach to retrieve the owner of the dataset. One way is to use the Power BI Rest API: https://api.powerbi.com/v1.0/myorg/datasets/{datasetId} which can provide the email address of the user who configured the dataset.
Now, to get the details of the overload, such as “how many times the dataset has raised an overloading” or “how much CPU has been used”, we can run another DAX query over the Premium App monitoring dataset as follows:
The results can be seen below:
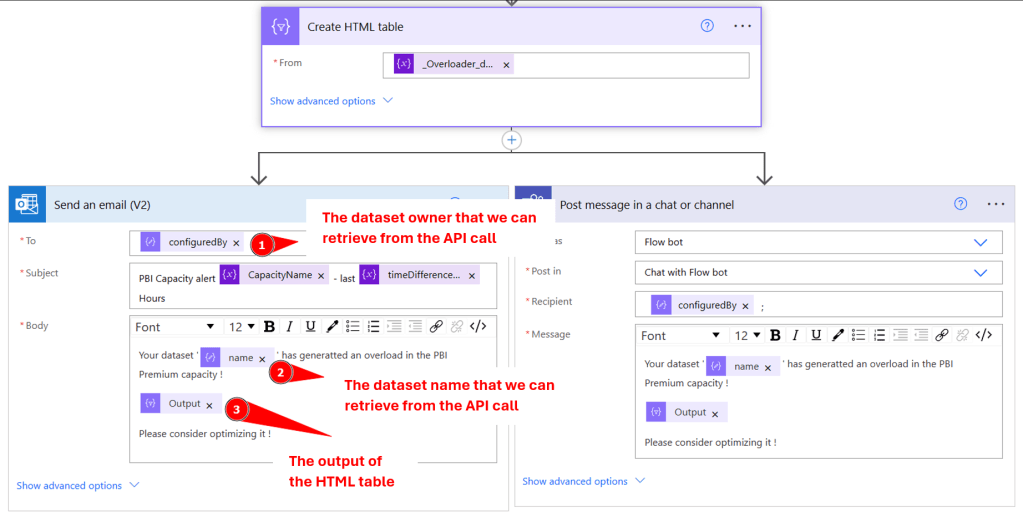
With all these information, we can notify through email or a Teams message, the owner of the dataset (extracted from the Power BI rest API), with all the required information to handle the overload. It is also possible to save all these information periodically (in a Blob storage, DWH, CSV files, etc.), so that we can analyze the “bad students” of the Premium capacity and help them optimize their data model.
Overloaders detection on Power BI Premium: Setting the scene with Power Automate
For this example, we are going to use Power Automate to automate the e-mail/Teams notification to the owner of dataset who caused an overload in the last 24 hours with all the dataset consumption details.
Please note that Power Automate offers many ways to send notification or to store the data collected.
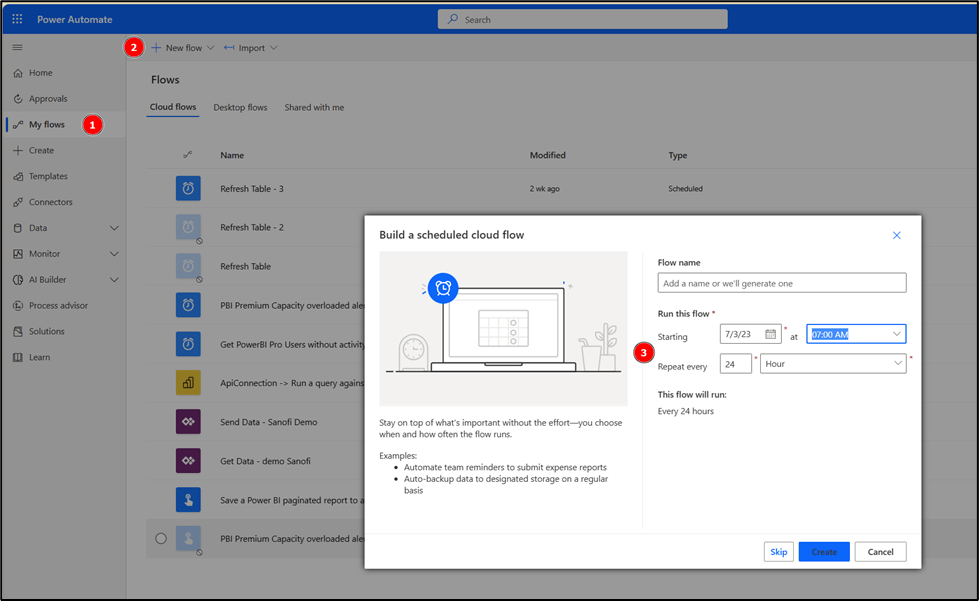
Once I logged into Power Automate, I will start by creating a flow with a scheduled Cloud Flow. The idea again is to run this flow each morning to see the overloaders of yesterday:
Let’s first create 3 variables that will help us later with our configuration:
The first variable “CapacityName” will store the Premium Capacity ID
The second variable “timeDiffrence inHours” will store how many hours I want to look at ( in my case, I’m using 24 hours)
The third variable “Overloader details table” is an empty array that will be used to store the overloading details of each dataset so we can use it to send that to the owner.
After the creation of these variables, we will run our first DAX query in Power Automate by using the “Run a Query against a Dataset” Power BI action as follows:
Now that we have the IDs of the dataset that has caused an overloading in the last 24 hours, we will need to get their owner.
You can find all the details of creating such connector on this article: Power BI – Custom Refresh with Power Automate It’s not required to go through a Custom Connector. You could also use the HTTP Action but for reusability purpose it’s much easier with a custom connector.
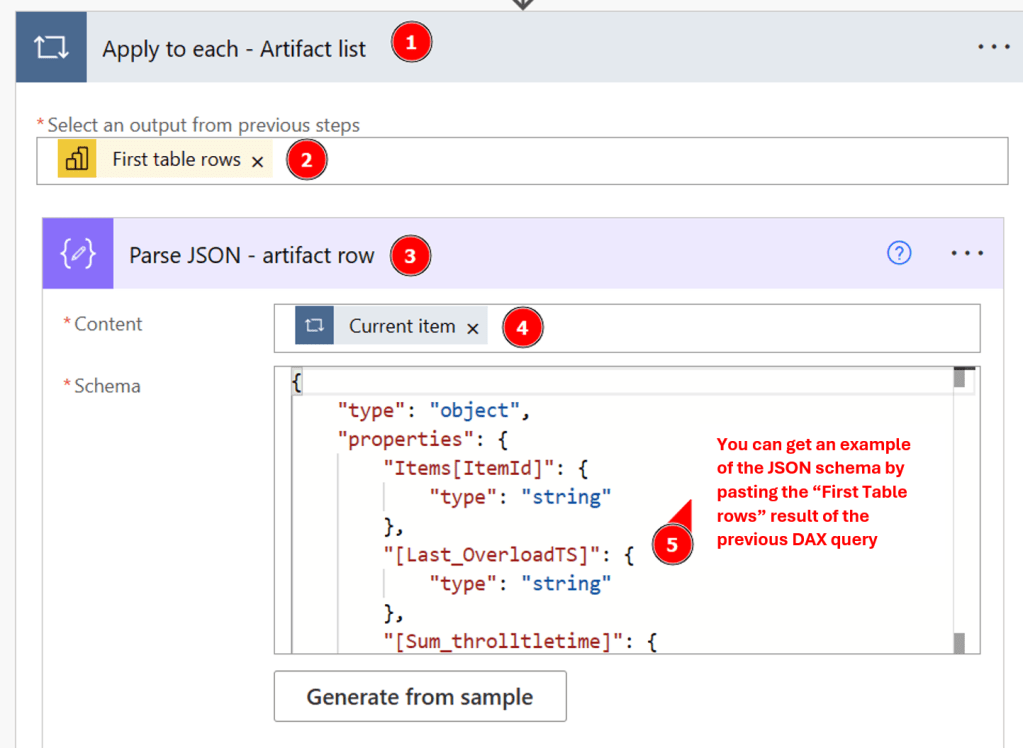
The “run a query against a dataset” action will return a JSON list that contains the IDs of the dataset. We will need to loop on each row in order to get their owner and run a second DAX query that will retrieve the overloading details. To do so, we will use “Apply to each” action in the flow and parse each “First Table rows” as follow:
After parsing the result of the DAX query, we will call the custom connector created earlier in order to get the owner of the dataset:
Now that we have the ID of the dataset parsed (Items[ItemID]) and the Owner of this dataset (ConfiguredBy), we can run our second DAX query to retrieve the details of overload of this dataset as follows:
Same thing here, we will need to parse the query result and use it to initiate our Table variable that will hold the throttling details for each dataset:
Now that we parsed our data and initiate a Table variable with the throttling detail (for only one dataset), we will create and HTML table that we can use in order to notify the dataset owner with the overloading that he created. Here you have the choice to either send and e-mail or Teams message, or even store the result in a SharePoint or Blob Storage:
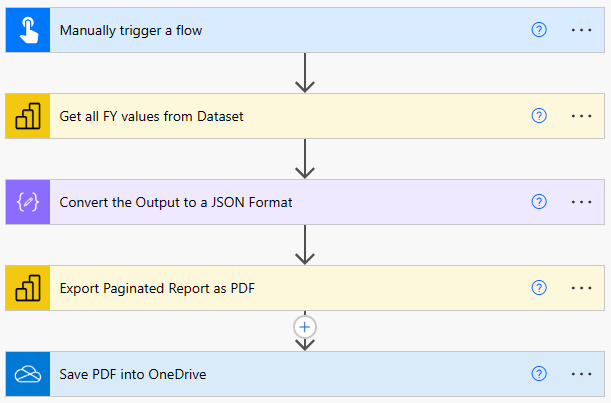
The full flow is presented as follow:
For this, we just used some DAX statement to identify the overloaders and combined the information afterwards with a REST API call to retrieve the Dataset owner. Obviously, there are multiple ways to achieve the same goal but I hope I showed you in a low-code manner how to achieve this goal.
Please let me know if this post was helpful and give me some feedback. Also feel free to contact me if you have any questions.
From time to time I got asked how customers can export Paginated (or Power BI) Reports automatically to store them e.g. in OneDrive or any other location. One way is obviously to do it manually, but we’re looking for an automatic way. So why not use the out-of-the-box Subscribe button within Power BI Service? Because it will send you an email and you can’t decide to store it somewhere else. Luckily, Power BI offers an API to achieve what we’re looking for. But what if I’m not a developer and don’t know how to write code e.g. in PowerShell or Python? No worries, Microsoft got you covered with Power Automate!
Prerequisites
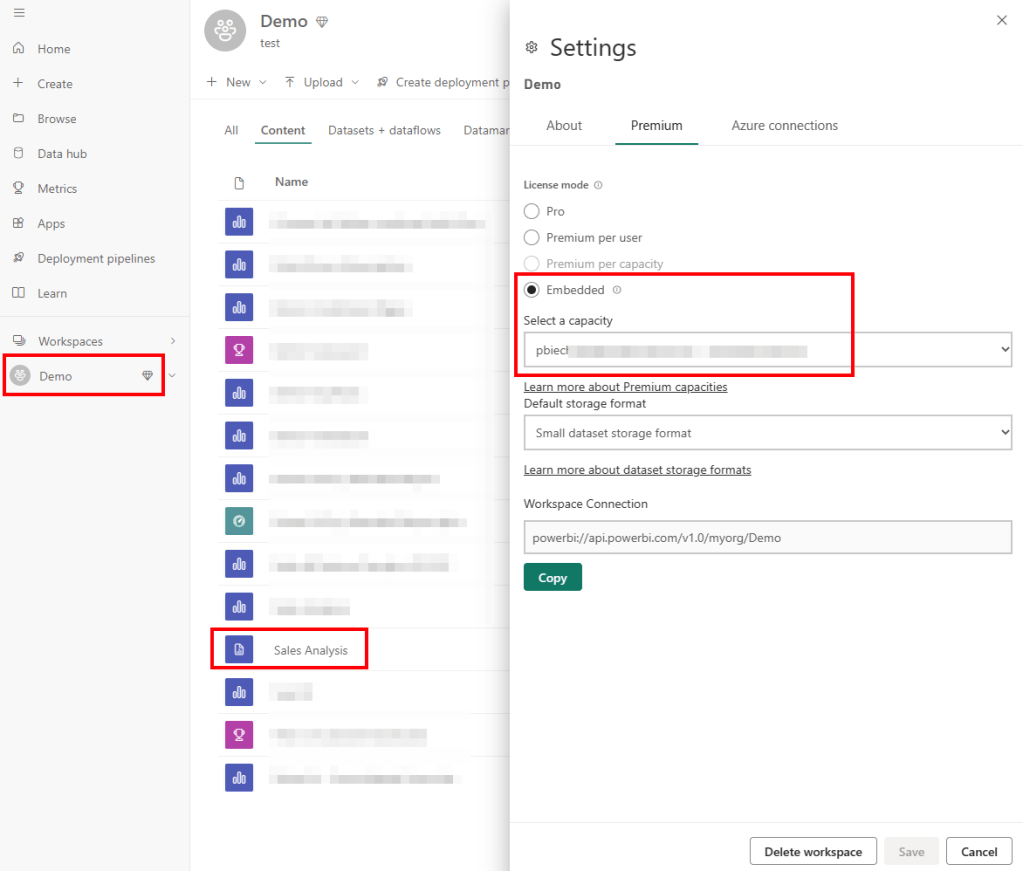
There are a few things which are needed to be able to follow this approach. First of all, Paginated Reports are part of a Power BI Pro license BUT if you wish to export a Paginated Report automatically, you still need a capacity (Premium or Embedded) to be able to do so. Reason is to make sure the end user is licensed in a proper way because through Premium the end user requires only a Free license. If you try to export a Paginated Report through the API backed up with a Pro license, you’ll get an error as you can’t make sure the end user also have a Pro license. That’s the reason why a capacity is needed. But buying Power BI Premium just to be able to export PDFs automatically is probably an overhead. Therefore we’re looking for a more cost-effective way which can be achieved with Power BI Embedded. Why? Because Power BI Embedded can be paused and it will not generate any cost at all! So we can turn it on just when needed, export our PDFs, and shut it down afterwards! Keep in mind while Embedded is paused the Reports in the associated workspaces will not be accessible.
So here’s a list of what we need:
Power BI Pro license
Power BI Embedded
Power Automate license
Service Principal with sufficient permission
Basic understanding of REST API
Basic know-how of DAX
Because we’re going to call the REST API to start and pause our Power BI Embedded capacity with Power Automate, the HTTP connector is needed which is Premium (as of February 2023). Therefore the O365 included licenses is not enough as “only” Standard Connectors are included.
For my example I’m going to reuse the Sales Analysis Paginated Report from the Paginated Report in a Day course. I want to create one PDF for each Fiscal Year automatically and save each PDF into OneDrive.
Further, I prepared a folder in OneDrive called “Demo” where I wish to save my PDFs.
Let’s get started with Power Automate
Once I logged in into Power Automate via https://flow.microsoft.com/en-us I select “+ Create” on the left hand side and select “Instant cloud flow”. This means I can trigger my flow manually which is handy during development. Once done, I can change the trigger to e.g. a schedule like every Monday morning at 7am. After the new window pop up, I name my Flow as wished (PBI Guy – Save PDF from Paginated Reports), select “Manually trigger a flow”, and hit the Create button.
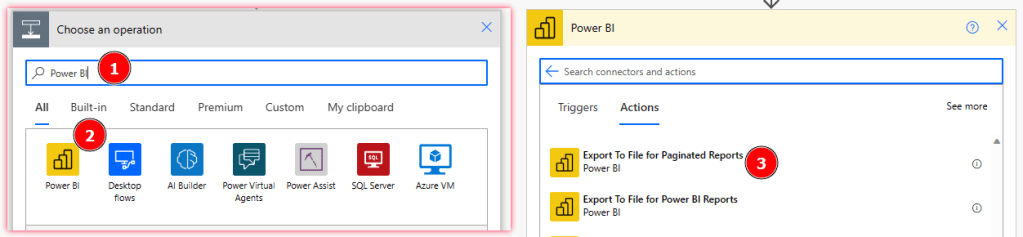
Let’s first test if I can save a PDF export into OneDrive and focus on starting & pausing the Capacity in a next step. So our first step is to get the PDF and then save it into OneDrive. To create a new action, just select the + New Step. Now, search for Power BI and select the build-in Power BI Connector. Once selected, scroll and search for “Export To File for Paginated Reports”.
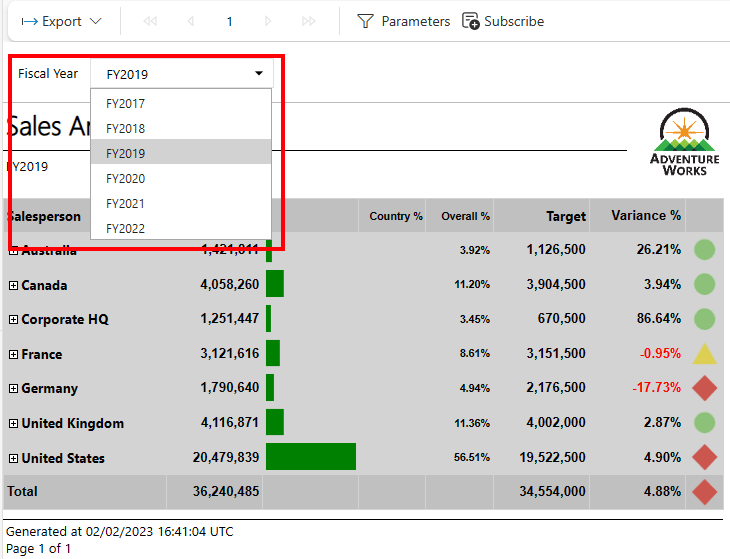
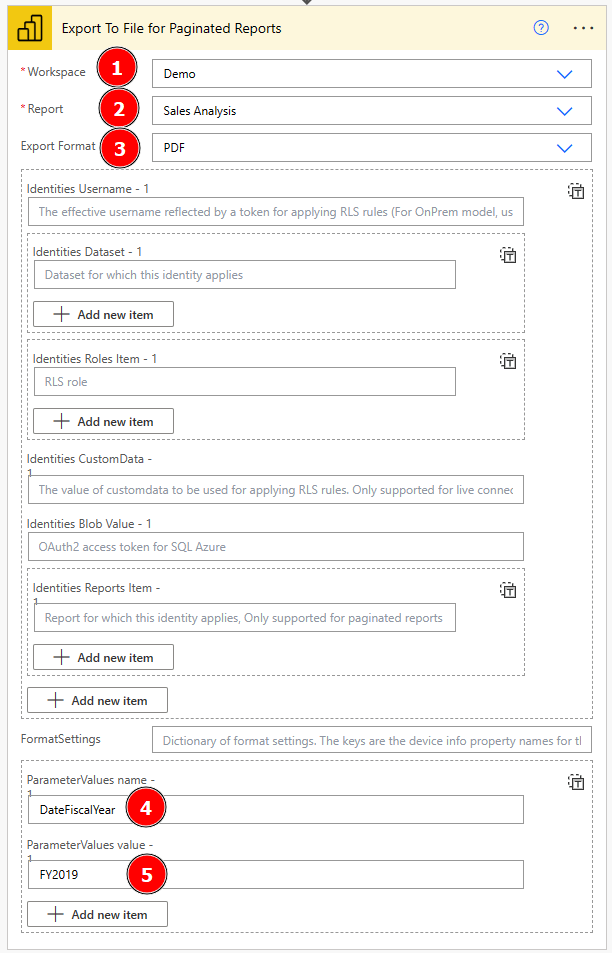
Afterwards, we have to configure our action by selecting our Workspace, Report, wished Export Format, and specify our Parameter which is Fiscal Year in this case. Be cautious by naming the Parameter as you need the internal name, not the label of the Parameter. Therefore you have to open the Paginated Report with Report Builder and check the internal Parameter name.
In my case it’s called “DateFiscalYear”.
Now that I have all needed details I switch back to my Flow and configure the action by selecting the Workspace (Demo), afterwards a list of my Paginated Reports will appear where I select the Sales Analysis, and choose my wished Export Format. Per default it’s PDF but you can also choose another option if you wish. Next, I provide the Parameter name and add a Value (FY2019) for testing purpose.
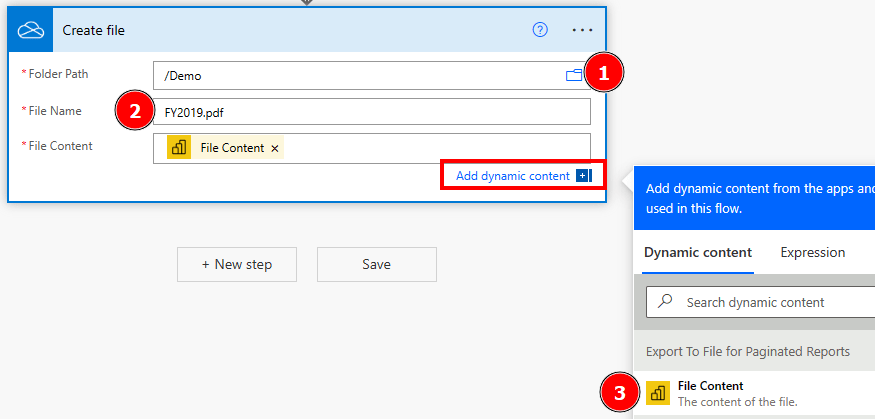
Next, I add a New Step by hitting the button, search for OneDrive, select OneDrive for Business, and select “Create File” as new action.
Afterwards, I just configure the Path by selecting the small folder icon and browse to my wished destination. I add FY2019.pdf as file name and choose the File Content from the dynamic content pane as File Content for my action. If you somehow don’t see the dynamic content, just hit the button at the bottom right to expand it.
Let’s test the flow and see if a PDF will be saved into OneDrive. To do so just click at the top right on the Test button. A new pane will appear, just select Manually and hit Save & Test.
Running it the first time I need to sign in to the different connectors I’m using (Power BI and OneDrive). Just Continue to do so and hit as last step Run Flow. Keep in mind that the Power BI Embedded capacity has to run otherwise you’ll get an error as the Report is not available.
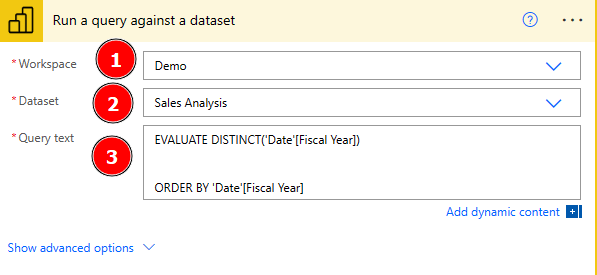
After approx. 1 Minute our Flow will finish and checking OneDrive I can see a new PDF has been created. Great! Opening it shows me that even the Parameter FY2019 has been passed and I see only FY2019 data – awesome! But now let’s parametrize it a little so my Flow will create a PDF for each FY available and not only FY2019. To do so I switch to Edit mode by selecting the appropriate button at the top right and add a new step right after our manual trigger by clicking on the + sign. I again search for Power BI and choose “Run a query against a dataset” as action. In here I select again my Demo workspace and Sales Analysis Dataset. The idea is now to run a DAX statement against the Sales Analysis Dataset to get all FY values which we will reuse to generate our PDF and save it. I quickly open DAX Studio, connect to my Dataset, and generate an EVALUATE DAX statement to get all FY values of my date table.
EVALUATE DISTINCT('Date'[Fiscal Year])
ORDER BY 'Date'[Fiscal Year]
I copy and paste the whole DAX statement into the query text of the action in my flow.
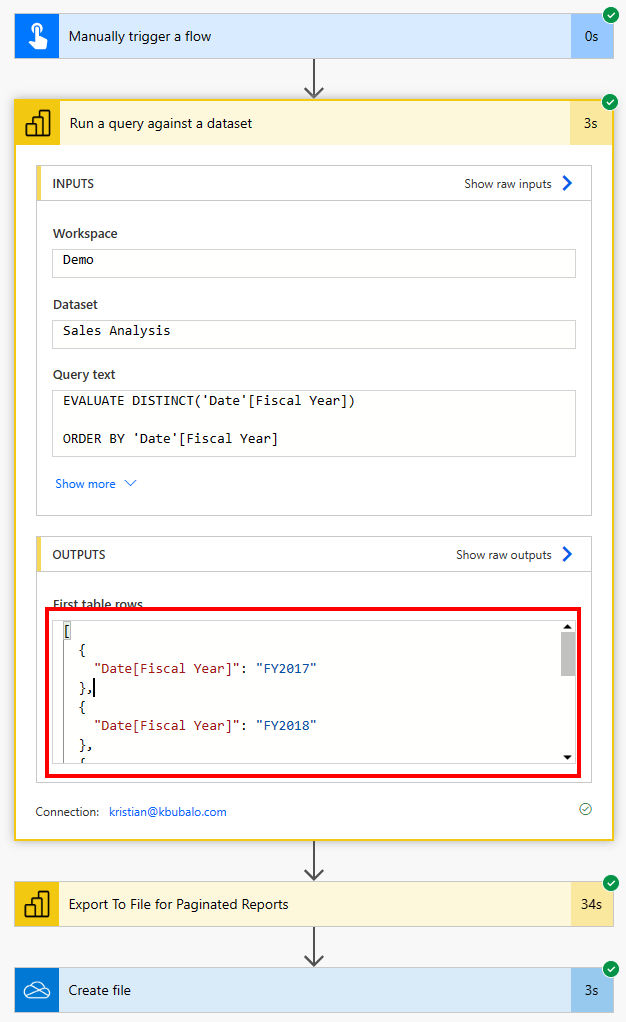
Again, to test if it works, I rerun the Flow and check the Output of my new action. As I can see there are different FY values as expected – perfect! I copy the whole output as we will need it for our next step.
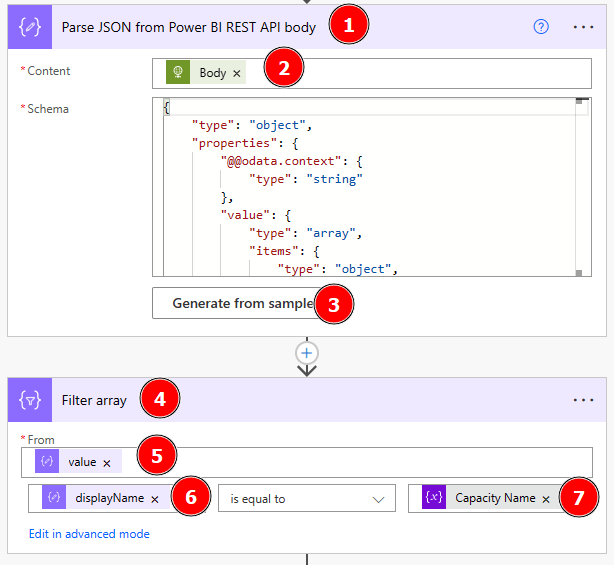
I switch back to Edit mode and add a new step between the two Power BI actions. I search for JSON and select the Parse JSON action. Next, I add into the Content field the “First table rows” dynamic content from my previous step. Lastly, I hit the Generate from sample button and paste the result I copied a few seconds ago. This will automatically create a schema.
This step is needed to be able to get each value and reuse it afterwards to create for each FY a PDF. Before I move to my next step, I want to rename my Actions making sure by just reading them each user can understand what is happening. To do so, just select the three dots for each step and rename it accordingly. In my case I renamed the steps as following.
Now, let’s parametrize our Export to reuse the FY values dynamically. To do so, I select the Export action, scroll down to ParameterValues value section, delete my hard coded FY2019 and add Date[Fiscal Year] as dynamic content from my previous step. This will automatically create a “Apply to each” around my step.
Next, I drag and drop the “Save PDF into OneDrive” action into the Apply to each container and position it below the Export action. Lastly, I delete the hardcoded file name and again add the Date[Fiscal Year] dynamic content and add .pdf at the end. Otherwise it will not be saved as such.
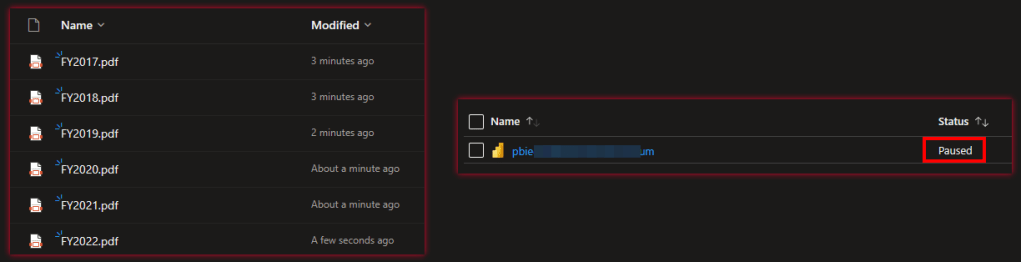
Again, let’s test our flow and check the result. After roughly 4 minutes our flow has finished and I see 6 different PDFs in my OneDrive, one for each FY – awesome!
Now we have to make sure to pause the Power BI Embedded Capacity once the job is done. Also, we want to make sure it starts once the flow has started otherwise the PDFs can’t be generated. Let’s first focus on starting the capacity.
The official Microsoft Documentation shows the necessary REST API call to start resp. resume the capacity. There are different parameters which are needed:
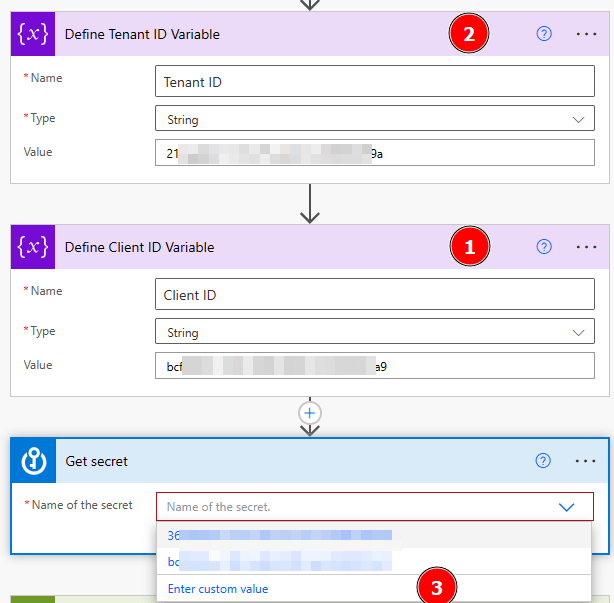
So let’s create these three parameters in our Flow to make it easier to use and reuse them. After switching back to my Flow I add a new action right after the trigger to create the parameters as a first step. I search for Variable and select “Initialize Variable”. I name the first variable “Subscription ID”, make it a String type and enter my Subscription ID as Value. If you don’t know the Subscription ID, just check it in your Azure Portal by selecting the Embedded Capacity.
I rename my action from Initialize variable to Define Subscription ID Variable and redo the steps for Resource Group Name and Dedicated Capacity Name Variables.
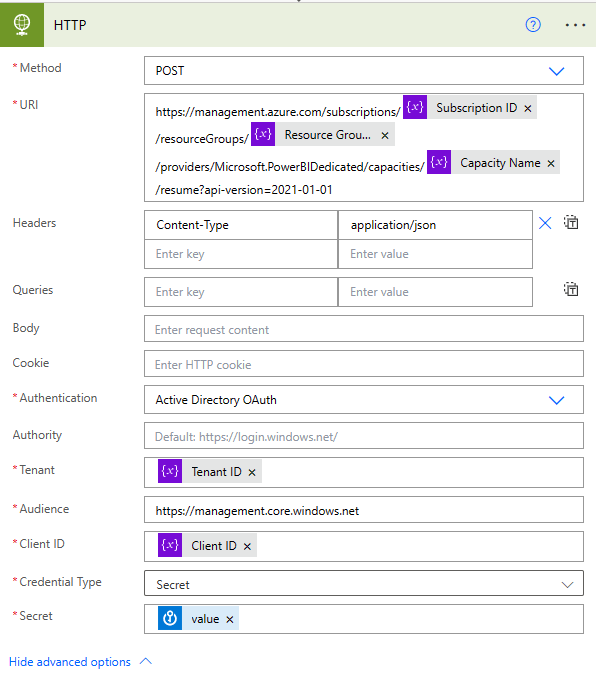
Now, let’s try to call the REST API with the HTTP action. Again, just hitting the + Button after my variables and search for HTTP. Once selected, I can configure it. The Method we have to use is POST based on the documentation. In the URI field I copy and paste the whole REST API call. Once copied, I delete the general parameter from the URL (everything between and including the {}) and replace it with the previously created variables from the dynamic content pane. In the Headers section, I add Content-Type as key and application/json as value. Because the REST API is not publicly available we have to log in somehow to be able to call it. Therefore, we can expand the advanced options and choose our authentication method. As I work mostly with Service Principals, I select Active Directory OAuth. Once selected, there are a few more things to fill out.
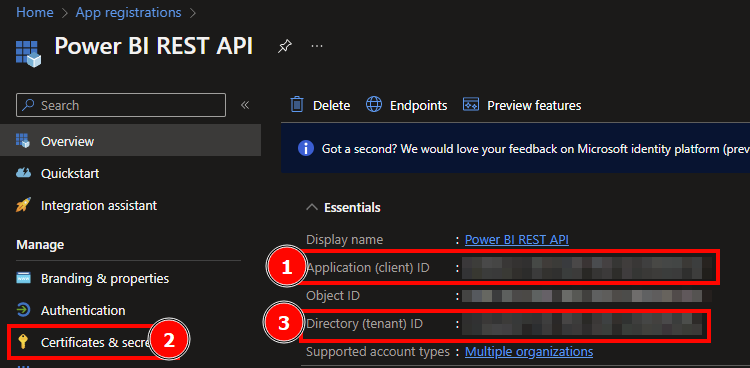
Let’s see how we can get the needed details. The Client ID as well as the Tenant ID can be found in the overview of the Service Principal.
The Secret can be generated from the Service Principal or, like in my case, I have it stored in Azure Key Vault so I add a new step before the HTTP Call to get the secret out of it. To do so, again, I hit the + button, search for Azure Key Vault, and select Get Secret. In there, I can select the different Service Principals I have access to but because I have to provide the Client ID in the HTTP request as well, let’s parametrize it and create a variable one step before called Client ID. Further, let’s add a variable for the Tenant ID as well. Once done, I can now use the variable within my Get Secret action by selecting Enter custom value and select the Client ID variable.
Further, I can now add the variables to the associated places in my HTTP action and use the value of my Secret action. Lastly, Audience have to be added which is in this case https://management.core.windows.net.
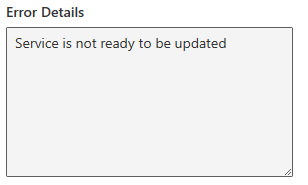
Let’s try and run our Flow to test it. If everything is set up correctly, you’ll get an error because the Power BI Embedded capacity is already running and you can’t start it again. Therefore following error will appear:
This means we need to check the status and, if it is paused, call the API, otherwise skip this part. And how can we check the status? Through REST API! Power BI offers an admin call to get all capacities (see https://learn.microsoft.com/en-us/rest/api/power-bi/admin/get-capacities-as-admin) We’re going to call it and check the status. So let’s create another HTTP request above the current one. This time, according to the documentation, we use a GET method and paste https://api.powerbi.com/v1.0/myorg/admin/capacities into the URI field. As headers we use again Content-Type as key and application/json as value. To be able to authenticate I’m going to use again my Service Principal and luckily, I have everything stored in variables so I can just put them into the right place. Only the audience will change this time as we’re connecting to Power BI now, not to Azure, therefore I have to use https://analysis.windows.net/powerbi/api for it.
If I run the Flow now, it will still fail at the second HTTP action, but I get the result of the Power BI REST API and can check what the status is of my Embedded Capacity.
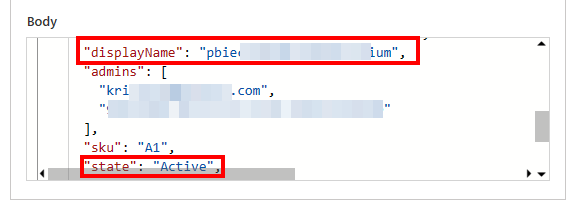
As a next step, I want to filter the result to only my capacity and extract the status. To be able to do so, I have to parse the body again to JSON and filter it afterwards. So, I copy again the whole body from the HTTP request and switch back to Edit mode. Once there, I add a new step after the Power BI REST API call and search for JSON and select Parse JSON. As content, I add the Body and generate the schema from a sample again by pasting it into the window after I hit the Generate from sample button. Now we have generated an Array which can be filtered. Therefore as next step I search again for Filter Array and select it. I put value from my previous step into From, select displayName as value on which I wish to filter and say it should be equal to my variable Capacity Name.
Now, that we filtered our result down to our desired capacity, we can do a check on the status. Let’s add a new step and search for Condition. In there, I add state from my previous step and configure is equal to “Active”. Once state is added as dynamic content, an Apply to each container will be automatically created. Just leave it as it is.
As next step, I drag and drop the HTTP request to start my capacity into the “If no” stream. This means, if the status is active, I don’t have to call the API to start it but if it’s not active, I would like to start it via REST API. As Power Automate will not wait until the Capacity is running and just continue to the next step, I want to make sure the capacity is in the desired state by adding a delay action of 30 seconds. Obviously, I could create a loop calling the Power BI REST API checking the status and, once changed to active, to proceed, but I’m not interested in the most performant way to execute this Flow but rather in an efficient, low-code way. Therefore the easiest method is to just add a delay.
Let’s one more time test our Flow making sure it’s working as expected. You’ll see, because the capacity is still running, it will go the “If yes” path and not call the REST API this time to start it. Therefore no error occurred and the PDFs have been generated again – great! And as you see the PDFs have been overwritten as we’re using the same name. This is expected behavior.
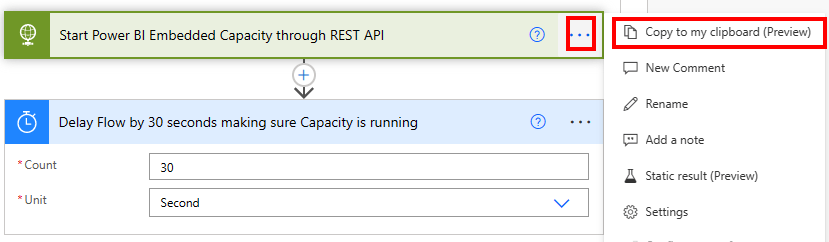
As a last thing we have to make sure now that our capacity will pause once the Flow is done. Again, checking the documentation there is almost the identical REST API call to pause resp. suspend the capacity. All we need to do is change “Resume” to “Suspend”. To be as sufficient as possible, let’s go to our Start Power BI Embedded action, hit the three dots, and choose Copy to my clipboard.
Now, I hit the + New step at the bottom of my flow, switch to My clipboard and select the copied action.
All I have to do now is to rename it and adjust the URI. What a time saver!
That’s it! Let’s test our final Flow by running it again. After roughly 4-5 minutes the Flow is done and I see on one hand that new PDFs have been created in my OneDrive and on the other hand my Power BI Embedded Capacity is now paused.
Let’s run it again making sure if the capacity is paused that the Flow will start it, still create the PDFs, and then shut it down. And again, after like 5 minutes it was successful. Checking the condition action in the Flow, we see the expression was false (capacity status is not active) and it went the right path to start it – perfect! During the run you could also refresh the page in Azure Portal to check the status of your capacity and you’ll see how it changed from Paused to Active and back to Paused.
The really last thing now is to delete the manual trigger at the top and replace it with what’s needed. E.g. a Schedule to run it every Monday 7:00am like in this example. Obviously, you can also choose other triggers depending on your needs. Keep in mind that Power BI offers a Power Automate visual out-of-the-box which can be used to trigger our Flow as well – from insights to action!
Please let me know if this post was helpful and give me some feedback. Also feel free to contact me if you have any questions.
In recent discussions with customers, I was asked if there is an automatic way to assign workspaces to dedicated capacities like Power BI Premium or Embedded. Obviously, you can do it manually through the Power BI Admin Portal, but how can you automate it in a scenario where you have to assign hundreds of workspaces based on different conditions? I’m sure you know my answer for this question: Through the Power BI REST API! Let me walk you through how to achieve it.
Prerequisites
You’ll need a few things to be able to automate this need.
Service Principal
A dedicated capacity (Power BI Premium, Embedded, or Premium per User license)
Python skills
Understanding REST APIs
Setting the scene
For my demo purpose I’m going to use a Power BI Embedded capacity – a so-called A-SKU – from the Azure Portal. If you’re interested in how to create an Embedded capacity, follow this link.
Further, I’m going to reuse my already created Service Principal (SP). I blogged about how to create a SP, what kind of settings in your Power BI Service you need to enable, and what kind of permissions are needed here.
Lastly, I have to make sure my SP can assign workspaces to the capacity. Regarding the documentation (see here) the SP needs admin rights on the workspace as well as capacity assignment permissions to that capacity.
Unfortunately, the Admin REST API does not support (yet?) Service Principals to assign workspaces to a capacity. Therefore, we have to make sure that the SP is admin of each workspace we wish to move to a capacity. Luckily, there is an Admin API to assign yourself as Admin or a SP to a workspace (see here). If you’re interested in a blog about assigning a SP to different workspaces, let me know and I’ll be happy to blog about it.
So, let’s make sure the SP has sufficient permissions.
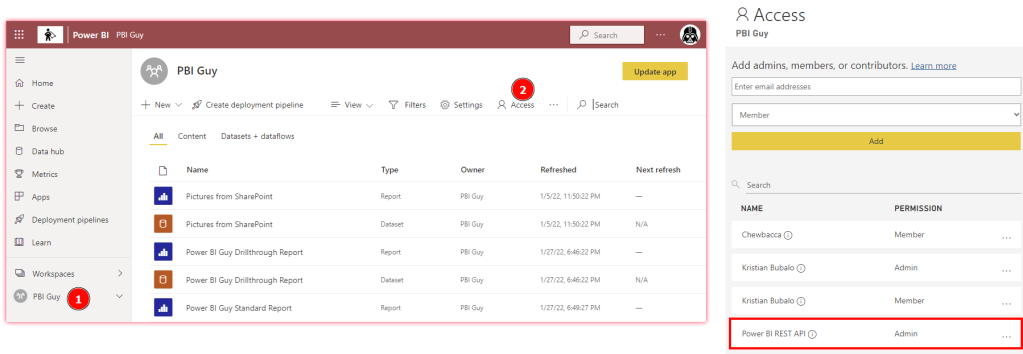
Add SP as Admin to a workspace
This step is pretty easy and straight forward. Just head over to powerbi.com, select your workspace, click on Access, and make sure your SP is added as Admin.
As you can see in the screen shot above, the workspace is not assigned to a capacity yet otherwise it would have a diamond sign right to the workspace name (PBI Guy).
Add SP as Capacity Admin
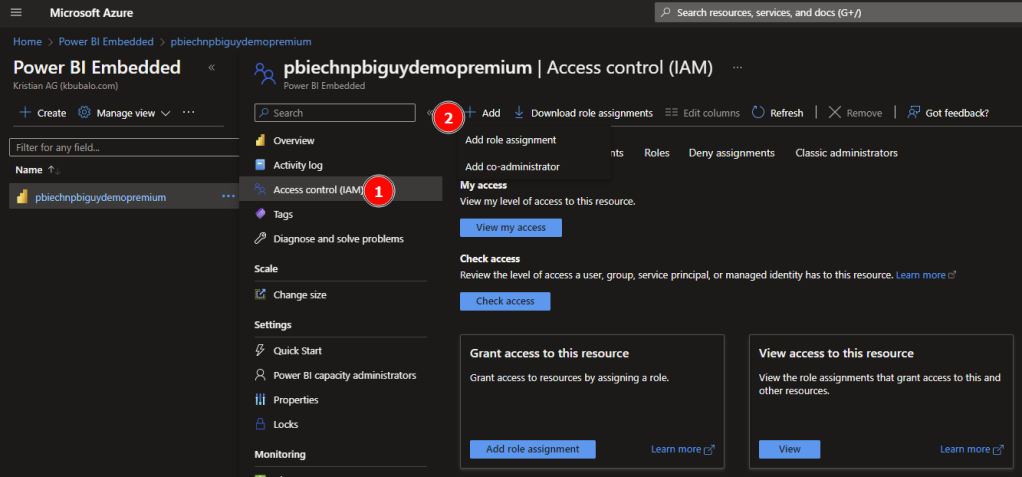
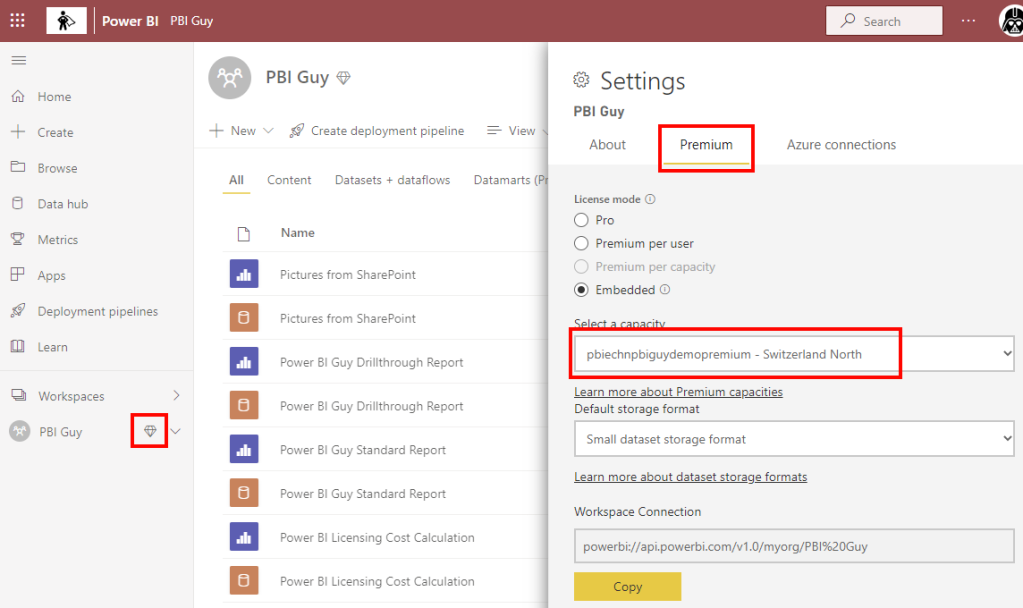
In the case of Power BI Embedded you can’t differentiate between admins and contributors like with Premium. Therefore, I have to add the SP as admin in the Azure Portal. To do that I just log in to the Azure Portal, select my Power BI Embedded capacity, and click on Power BI capacity administrators. Once there, click + Add, search for your SP and add it. That’s it. Just make sure your Embedded Capacity is running otherwise you can’t add a new admin.
Further, we have to make sure the Service Principal is allowed to start and pause the embedded capacity. This is done through the Access control on the left-hand side of the pane. Once selected, click + Add and select Add role assignment.
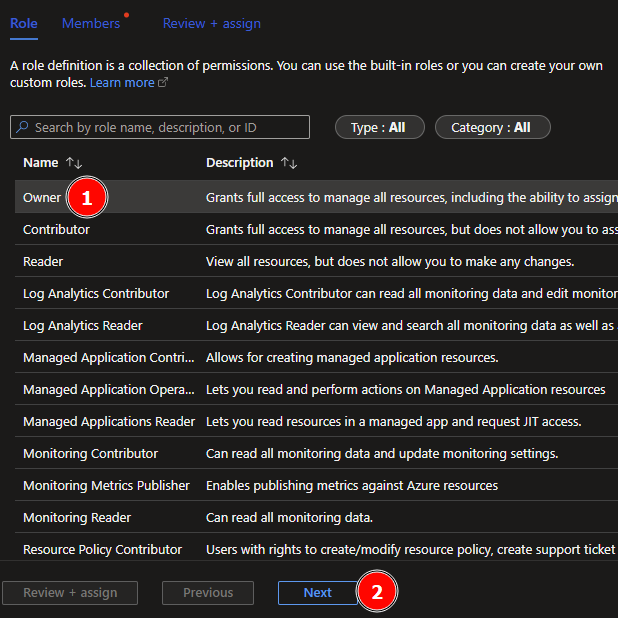
Next, select the needed role. In my case I just give the SP Owner rights but Contributor would be sufficient as well. Once selected, hit next.
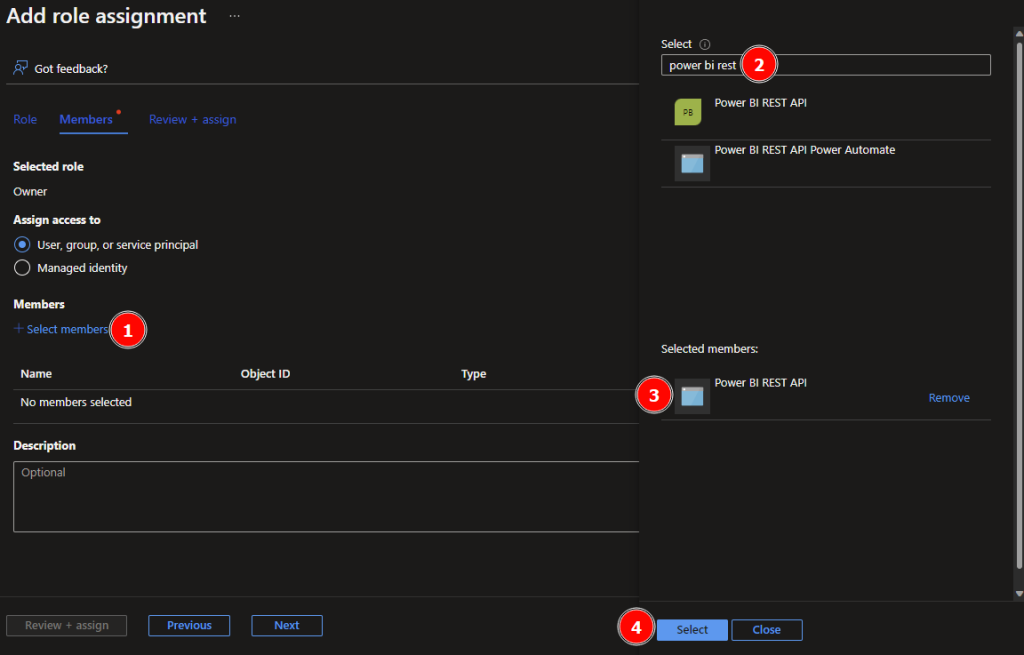
On the next screen just select the + Select members, search and add the SP to it. Click select to proceed.
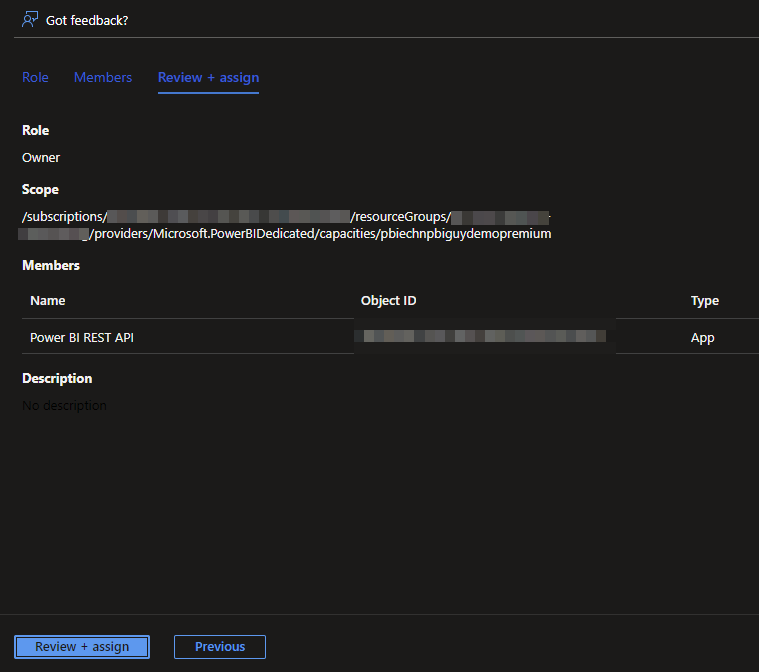
Lastly, hit Review + assign to check your configuration.
If everything looks as expected, hit Review + assign again. We’re now good to go and create our Python script.
It’s time for magic!
As usual, in my first block of code I’m going to import the needed libraries.
#Import necessary libraries
import msal
import requests
import json
import pandas as pd
import time
from azure.identity import DefaultAzureCredential
In my second block, I specify all required variables which we will use later on.
#Set variables
client_id = "" #Service Principal ID
client_secret = "" #Secret from Service Principal
tenant_id = '' #Tenant UID, can also be found in the Service Principal Overview under "Directory (tenant) ID"
domain = '' #Your domain name
authority_url = "https://login.microsoftonline.com/" + domain
scope = ["https://analysis.windows.net/powerbi/api/.default"]
subscriptionId = '' #Subscription ID on which the PBI Embedded is running
resourceGroupName = '' #Resource Group Name in which the PBI Embedded capacity has been created
The client id, secret as well as the tenant id can be found in the Overview page of your SP.
The domain is everything behind the @ of your email address, e.g. kristian@pbiguy.com would mean “pbiguy.com”.
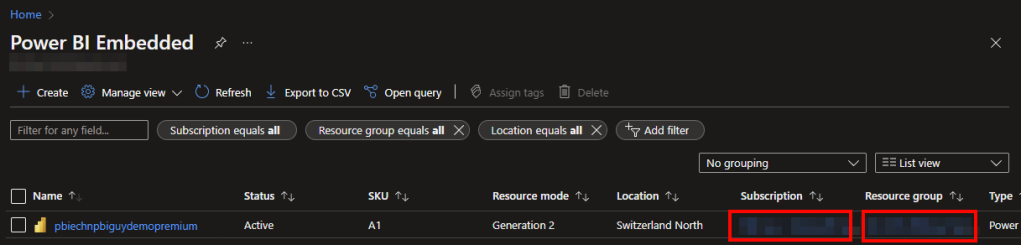
Authority URL and the scope shouldn’t be touched as those are needed to authenticate for the PBI Service. Lastly, the subscription name and resource group name can be found in the Azure Portal on the Power BI Embedded Services overview.
Just keep in mind to use the Subscription ID, not the name!
Next piece of code is to grab a token on behalf of the SP.
#Use MSAL to grab token
app = msal.ConfidentialClientApplication(client_id, authority=authority_url, client_credential=client_secret)
result = app.acquire_token_for_client(scopes=scope)
In my next step, I want to list all capacities I have access to. Because I’ll need to do that twice within the code (explanation will follow), I create a function, so I don’t have to duplicate my code. The function returns a Pandas DataFrame with all capacities incl. further details.
#Function to get all available capacities
#Power BI Premium Per User will also be listed as capacity separately
def get_all_capacities():
"""Get all available capacities the user has access to.
Power BI Premium per User will be listed separately.
Returns a Pandas Dataframe with Capacity ID, Name, Admins, SKU, state, User AccessRight, Region, and Users."""
url_get_all_capacities = "https://api.powerbi.com/v1.0/myorg/admin/capacities"
if 'access_token' in result:
access_token = result['access_token']
header = {'Content-Type':'application/json', 'Authorization':f'Bearer {access_token}'}
api_call = requests.get(url=url_get_all_capacities, headers=header)
result_value = api_call.json()['value']
df_all_capacities = pd.DataFrame(result_value)
return df_all_capacities
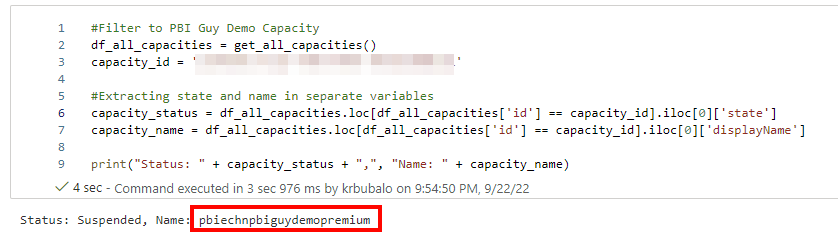
Next, I want to select my desired capacity, which is in my case the Power BI Embedded one. So, I call the function to get all capacities and filter the result, based on the capacity id, to my Embedded one. Making sure the right one is selected, I print out the capacity name as well as the status (is it running or paused).
#Filter to PBI Guy Demo Capacity
df_all_capacities = get_all_capacities()
capacity_id = '163A01FC-6115-4305-9007-A03391B0B151'
#Extracting state and name in separate variables
capacity_status = df_all_capacities.loc[df_all_capacities['id'] == capacity_id].iloc[0]['state']
capacity_name = df_all_capacities.loc[df_all_capacities['id'] == capacity_id].iloc[0]['displayName']
print("Status: " + capacity_status + ",", "Name: " + capacity_name)
The result is as desired, and I only selected my Embedded capacity.
Now that I got the needed capacity, it’s time to get all workspaces I wish to assign to this capacity. Therefore, my next step is to call the REST API to list all workspaces the SP has access to. To get an overview, I display the DataFrame at the end.
#Get all Workspaces the user has access to
url_get_all_workspaces = 'https://api.powerbi.com/v1.0/myorg/groups'
if 'access_token' in result:
access_token = result['access_token']
header = {'Content-Type':'application/json', 'Authorization':f'Bearer {access_token}'}
api_call = requests.get(url=url_get_all_workspaces, headers=header)
result_value = api_call.json()['value']
df_all_workspaces = pd.DataFrame(result_value)
display(df_all_workspaces)
For my purpose, I filter the workspaces to only include those with “BI” in the name. Of course, you can create further conditions and filter options based on your needs.
#Filter to needed workspaces. In this case all workspaces with "BI" in the name will be used.
df_selected_workspaces = df_all_workspaces[df_all_workspaces['name'].str.contains('BI')]
display(df_selected_workspaces)
Again, I display the DataFrame at the end to check my filter and selection. Looks good so far.
Let’s do a quick recap what we achieved so far. We have our capacity selected to which we want to assign our workspaces. We also selected all the workspaces we wish to assign to our capacity. As a next step, we have to assign them. But before doing so, especially in the case of Power BI Embedded, we have to make sure that the capacity is running and not paused. Thus, my next block of code will check the status and if it’s paused (suspended), I’ll start (activate) it. This step is not necessary for Premium capacities as they are always active.
I’ll first create a function to get an Azure token. This one differs from the Power BI one as we have to log in into Azure and not Power BI.
Next, I define a function to create the URL to start or pause the capacity. As the REST API URL is very similar and only the last piece (status variable) differs, it’s much more efficient due to reusability reasons to work with a function in this case.
Lastly, I use the capacity status from my previous code to check if it’s suspended. If so, I call the previously created function to create an Azure Token and call the REST API to resume the capacity. At the end of the code, I print out a message based on the status code received.
#Check status of Capacity
#If Suspended, Resume it to be able to assign workspace
def get_az_token(tenant_id, client_id, client_secret):
"""Function to get an Azure Token.
3 variables are required: tenant_id, client_id, and client_secret."""
data = "grant_type=client_credentials&client_id=" + client_id + "&client_secret=" + client_secret + "&resource=https%3A%2F%2Fmanagement.azure.com%2F"
url = "https://login.microsoftonline.com/" + tenant_id + "/oauth2/token"
response = requests.post(url, data=data)
AccessToken = response.json()["access_token"]
return AccessToken
def create_url (subscriptionId, resourceGroupName, pbiCapacityName, status):
"""Function to change status of capacity.
Required variables are subscriptionId, resourceGroupName, pbiCapacityName, and status."""
url = 'https://management.azure.com/subscriptions/' + subscriptionId + '/resourceGroups/' + resourceGroupName + '/providers/Microsoft.PowerBIDedicated/capacities/' + pbiCapacityName + '/' + status + '?api-version=2021-01-01'
return url
if capacity_status == 'Suspended':
azToken = get_az_token(tenant_id=tenant_id, client_id=client_id, client_secret=client_secret)
url = create_url(subscriptionId, resourceGroupName, capacity_name, 'resume')
header = {'Content-Type':'application/json', 'Authorization':f'Bearer {azToken}'}
api_call = requests.post(url=url, headers=header)
if api_call.status_code == 202:
print('Successfully changed status to resume.')
if api_call.status_code == 400:
print('An error occured. Probably the capacity is already in status running.')
if api_call.status_code == 403:
print('No sufficient permission to perform this action. Make sure the user has enough right on Capacity.')
As it takes some time to activate the capacity, I’ll check in my next code block if the capacity is really active. Otherwise, I would get an error message trying to assign a workspace to a suspended capacity. Now, I call the get_all_capacities function to get again all capacities, filter down to my desired one, and save the status in a separate variable called capacity_status. Next, I do a while loop if the status is suspended and check all 5 seconds until the status has changed to active. This way I make sure the capacity is really in active stage.
#Check status of Capacity, wait until it changed
df_all_capacities = get_all_capacities()
capacity_status = df_all_capacities.loc[df_all_capacities['id'] == capacity_id].iloc[0]['state']
while capacity_status == 'Suspended':
print("Capacity is still suspended. Checking status in 5 seconds again.")
time.sleep(5)
df_all_capacities = get_all_capacities()
capacity_status = df_all_capacities.loc[df_all_capacities['id'] == capacity_id].iloc[0]['state']
if capacity_status == 'Active':
print("Capacity is active.")
break
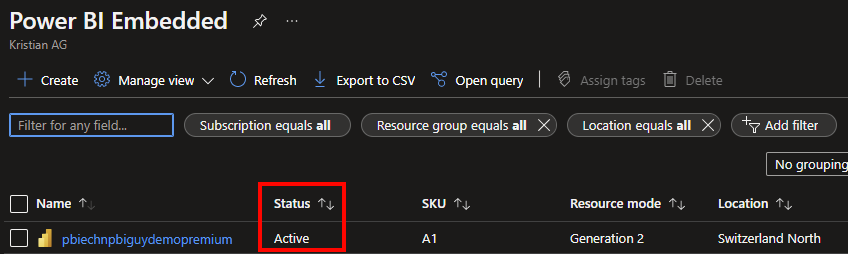
Let’s check in the Azure Portal, if the capacity is really running. I select the general overview of the Power BI Embedded service and see that my embedded capacity has an active status – great!
Finally, I can assign now my workspaces to the capacity. I create a for each loop on my selected workspaces DataFrame to assign each workspace obviously to the capacity (bulk update is not supported through the API). In the loop I extract the workspace ID and the name, update the URL for the REST API call (including the workspace ID), and specify the required body. In there, you’ll find the capacity_id variable specifying to which capacity we wish to assign the workspace. At the end I call the REST API and provide a message based on the status code received. If it’s successful, I print out a message with the workspace and capacity name confirming it worked.
# If you wish to unassign the workspace and move it back to Power BI Service, use the zeros GUID capacity ID
#capacity_id = '00000000-0000-0000-0000-000000000000'
#capacity_name = 'Power BI Service'
for idx, row in df_selected_workspaces.iterrows(): #Iterate through each workspace
workspace_id = row['id'] #Store the workspace ID in a separate variable
workspace_name = row['name'] #Store workspace name in a separate variable
#configure URL to call to remove license from user
url_assign_to_capacity = "https://api.powerbi.com/v1.0/myorg/groups/" + workspace_id + '/AssignToCapacity'
body_assign_to_capacity = {
"capacityId": capacity_id
}
if 'access_token' in result:
access_token = result['access_token']
header = {'Content-Type':'application/json', 'Authorization':f'Bearer {access_token}'}
api_call = requests.post(url=url_assign_to_capacity, headers=header, json=body_assign_to_capacity)
if api_call.status_code == 200:
print('Workspace', workspace_name, 'successfully assigned to new Capacity:', capacity_name)
if api_call.status_code == 400:
print("Power BI returned a Bad Request error. Make sure the capacity:", capacity_name, "is running to which you wish to assign the workspace to.")
if api_call.status_code == 401:
print("You don't have sufficient permission to assign this workspace to the desired capacity. Please make sure the Service Principal has contributor permission on the capacity and is admin of the workspace.")
If you wish to unassign a workspace from a capacity and put it back to Power BI Service (Shared Capacity), just use the 00000000-0000-0000-0000-000000000000 GUID for the capacity_id variable.
Let’s check in the Power BI Service if it really worked.
Great! First sign that it worked is the diamond icon right to the workspace name. Making sure the workspace is really assigned to the right capacity, I also check the workspace settings. Looks perfect!
My last step in the Python code is to pause the capacity making sure no additional or unnecessary costs will occur as I’m using the Power BI Embedded one. Depending on the number of workspaces, the Azure Token could be expired. Therefore, I want to make sure I have still an active one and call the get_az_token function again to get a fresh token. Afterwards, I call the create_url function but this time with the suspend status and save it to the url variable. Afterwards I call the REST API to pause it. Lastly, I again print out a message based on the response from the REST API.
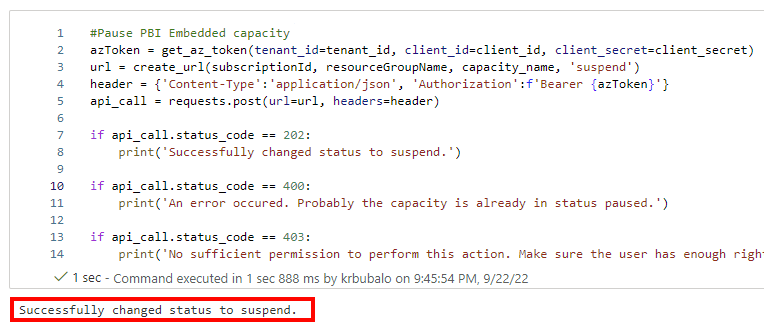
#Pause PBI Embedded capacity
azToken = get_az_token(tenant_id=tenant_id, client_id=client_id, client_secret=client_secret)
url = create_url(subscriptionId, resourceGroupName, capacity_name, 'suspend')
header = {'Content-Type':'application/json', 'Authorization':f'Bearer {azToken}'}
api_call = requests.post(url=url, headers=header)
if api_call.status_code == 202:
print('Successfully changed status to suspend.')
if api_call.status_code == 400:
print('An error occured. Probably the capacity is already in status paused.')
if api_call.status_code == 403:
print('No sufficient permission to perform this action. Make sure the user has enough rights on Capacity or make sure the capacity ID is not pointing to the Power BI Service with the zeros GUID.')
Once the code is executed, it looks like the status of the capacity has changed.
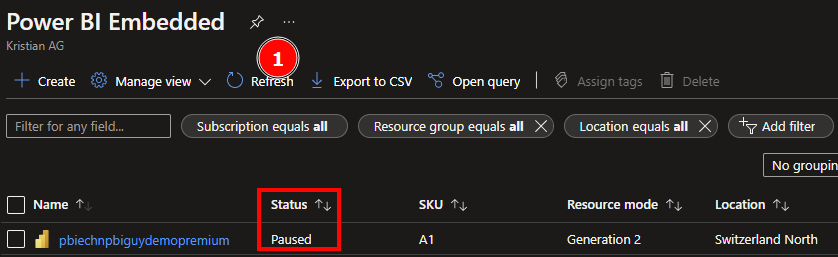
Let’s again check in the Azure Portal.
After hitting the refresh button, I see the capacity is really paused – excellent!
With this piece of code, I can automatically assign workspaces based on my needs to a specific capacity! As I worked with an Embedded one, I even automatically started and paused the capacity through the REST API – awesome!
Please let me know if this post was helpful and give me some feedback. Also feel free to contact me if you have any questions.
A few days ago, a colleague asked me if it would be possible to have more data from the Azure Cost Management API than only the last 30 days. Obviously, my first thought was sure, let’s use Azure Synapse and store it in a Data Lake. But then the real challenging question was asked: Would it be possible purely and only with Power BI, not with other services and tools? I was like: Let me brainstorm with my good colleague and co-organizer of the Power BI User Group Switzerland, Denis Selimovic. After a few minutes we (mainly him, but I’ll never admit it 😀 ) came up with the idea of using Datamarts as staging area and using Dataflows afterwards to enable Incremental Refresh. With this workaround, we’ll have an Azure SQL DB (this is technically a Datamart behind the scenes) as staging area, and therefore Incremental Refresh will work as Query folding will be possible! Denis already wrote a great article how to set it up for the Power BI Log Files, which only holds the last 30 days. Check it out here: https://whatthefact.bi/power-bi/power-bi-datamart/persisting-temporary-accessible-data-via-power-bi-datamarts-with-the-example-of-power-bi-activity-logs/ In my blog post I’m going to use a SharePoint site to test at the end the different scenarios (deleting, modifying, and adding new data). I just want to highlight one more time: This approach will work with any Data Source that Power Query / Datamart can connect to. So, it will also work with Excel Sheets, CSV files, BLOB, etc. What a game changer!
What is this Incremental Refresh, Query Folding, and why should I care?
Usually, if you connect to a data source with Power BI – and once your transformation and modelling is done – you set up an automatic refresh of the dataset. The beauty of this is, that all data will be refreshed every time. That works perfectly fine for small datasets. But what if you wish to only update the last few days because there is no need to refresh data from last years as those data never changes? For example, a sales report showing my sales from 2012 – 2022. Sales coming from the years 2012 – 2021 do not change usually so there is no need to update them on a regular base therefore we’re looking for a way to update only the last 7 days of 2022 in this example. This will speed up the Dataset refresh and that’s exactly what Incremental Refresh does. As creator of a dataset, you can set up how many days, months, or years you wish to refresh and everything older than that should just be stored. More insights about Incremental Refresh can be found here: https://docs.microsoft.com/en-us/power-bi/connect-data/incremental-refresh-overview
And how does Query Folding plays a role in this whole setup? Because we configure a specific date in our refresh (in our example we wish to refresh only the last 7 days of 2022), this date has to be provided somehow to the data source. If we’re talking in SQL, this means there has to be somewhere a WHERE clause filtering the data to the last 7 days. While Power BI connects to the data source, it tries to create Queries in the data source language (so if we connect to a SQL DB, it will talk SQL) and on top it tries to push all the different transformations that we did in Power Query to the data source. Again, as an example, if we rename a column from “Column A” to “Revenue” and our data source is SQL, it will generate something like SELECT [Column A] as [Revenue] so that SQL does the transformation. This is exactly what Query Folding is. It tries to push the transformations down to the data source. My friend and MVP Nikola Ilic did a great blog about Query Folding which you can find here: https://data-mozart.com/what-is-a-query-folding-in-power-bi-and-why-should-i-care/ or if you’re more interested in the Microsoft Docs following this link: https://docs.microsoft.com/en-us/power-query/query-folding-basics
Due to the fact that Incremental Refresh requires Query Folding to be able to get the latest data we’re looking for, not all data sources are supported. As an example, Excel, BLOB, CSV files, can’t be incrementally refreshed until now!
A datamart creator can use the no code experience to extract, transform, and load data into a database that is fully managed by Power BI. There’s no need to worry about creating and managing dataflows or data refresh schedules—it’s all automatic. The user gets an intuitive SQL and visual querying interface for performing ad-hoc analysis on the data. Users can then connect to the datamart using external SQL-aware tools for further analysis.
Therefore, we can connect to any data source, load it into a Datamart, and store it technically in a Database. Because now we have our data in our database, we can connect to it with a Dataflow and set up Incremental Refresh as Query Folding is now supported!
Let’s create a Datamart
As of today, Power BI Datamart is in Public Preview and a Premium feature so Premium, Premium per User, or Embedded is required. In my case I’m going to use a PPU license to create a Datamart. To be able to do so, I log in to PowerBI.com and select my demo workspace PBI Guy. In there, I choose New and select Datamart.
For the purpose of this blog post, I’m going to use a SharePoint list but as mentioned already, you can easily use something else like an Excel Sheet, CSV file, etc.
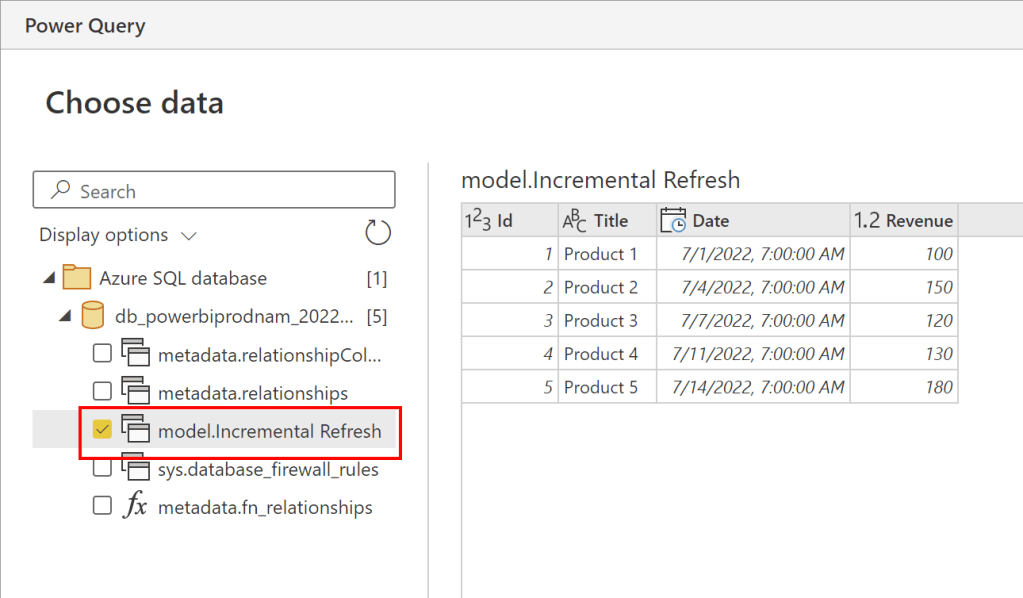
Therefore, I have to select Get data from another source and choose SharePoint Online list afterwards. Once selected, I provide my SharePoint site and my credentials, select my list, and hit transform data.
In Power Query Online I select only the needed columns (ID, Title, Date, and Revenue) and make sure that all data types are correct. As Incremental Refresh requires a DateTime column, please ensure your date column is set up correctly.
Once done, I select to load the data into my Datamart, and rename it on the next screen to “Staging Datamart” by selecting the arrow at the top.
Next, I create a Dataflow which should connect to my Datamart. Before I do so, I go back to my workspace, select the three dots besides my newly created Datamart, and hit Settings.
In there, I expand Server settings and copy the string.
Now I head back to my workspace, select New, and choose Dataflow.
On the next screen, I select Add new Table, and search for Azure SQL Database.
Once selected, I provide the copied Datamart (Azure SQL) string connection as Server name, select Authentication kind “Organizational account”, and select Next.
On the next screen, I select my table, and check in the Preview window if the data is correct. Once approved, I select Transform data.
In the Power Query Online experience, I don’t have to adjust anything anymore, but it would be possible if needed. Therefore, I just select Save & close, and save my Dataflow on the next screen with the name “Incremental Refresh”.
As next step, I have to configure Incremental Refresh. Luckily, this is pretty straight-forward. I just select the Incremental Refresh button, turn it on, and choose my Date column within the Dataflow as the DateTime column needed.
Lastly, I configure to store the past 3 years and only refresh the last 7 days. After hitting save I finished the configuration.
Once saved, a window pops up at the top right to Refresh the Dataflow now. I do so by selecting the button Refresh now to load the data into the Dataflow.
It’s time to test
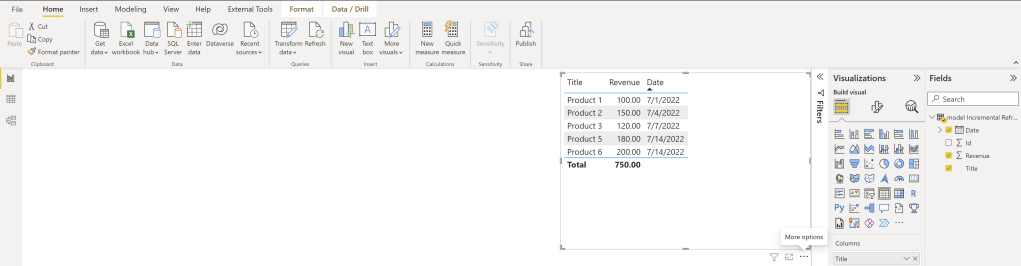
Now that we have set up everything (connecting with a Datamart to our data source, connecting a Dataflow to our Datamart and setting up incremental refresh) let’s test if it works as expected. Today is the 14th of July 2022. In my demo list, I have some sales starting 1st of July until today. If I connect now with Power BI to my Dataflow, I see all five entries coming indirectly from SharePoint – so far so good.
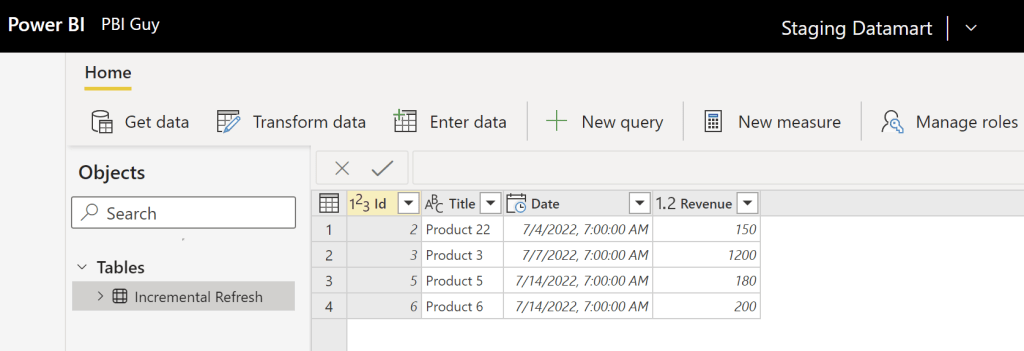
Now, let’s do some changes in the SharePoint list. I will delete two rows, one from the 1st of July and one from the 11th of July. Further, I changed Product 2 name to Product 22 on the 4th of July and updated the Revenue on the 7th. Lastly, I added a new sale for today.
Our first step is now to trigger a refresh for our Datamart. Once the refresh successfully finished, we see a 1:1 copy of our SharePoint list.
Now, let’s trigger a refresh of our Dataflow. Once it’s finished, I hit the refresh button in my Power BI Desktop, which is connected to the Dataflow, to see the end result.
And as expected, Product 1 and 2 haven’t changed! So, we have now some historization in Power BI – awesome! But let’s analyze each row to understand the behavior.
Because we set up the Incremental Refresh to refresh only the last 7 days, everything prior to it will be ignored. Because Product 1 and 2 are older than 7 days, the changes didn’t affect our data in the Dataflow. But what about Product 3 which is dated 7th of July? This is, from an Incremental Refresh Point of view, 8 days ago because
14. July = Day 1
13. July = Day 2
12. July = Day 3
11. July = Day 4
10. July = Day 5
09. July = Day 6
08. July = Day 7
and therefore, 7th July hasn’t been updated neither in our refresh. Product 4, which was dated on the 11th of July, has been removed – this is as expected. And lastly, our newest sale from today has been added (Product 6) which is also as expected.
Great, this is a real game changer as with Power BI you can now create a real staging area, and on top use Incremental Refresh to historize your data! But keep in mind, with this approach the data will only be available in the Dataflow. I would highly recommend using at least your own Azure Data Lake Storage Gen2 to store the Dataflow into it (see https://docs.microsoft.com/en-us/power-bi/transform-model/dataflows/dataflows-azure-data-lake-storage-integration). This way, you can access and enhance it if needed. Further, you can do backups and make sure it will not be lost if you delete your Dataflow.
Please let me know if this post was helpful and give me some feedback. Also feel free to contact me if you have any questions.