A few days ago, a colleague asked me if it would be possible to have more data from the Azure Cost Management API than only the last 30 days. Obviously, my first thought was sure, let’s use Azure Synapse and store it in a Data Lake. But then the real challenging question was asked: Would it be possible purely and only with Power BI, not with other services and tools? I was like: Let me brainstorm with my good colleague and co-organizer of the Power BI User Group Switzerland, Denis Selimovic. After a few minutes we (mainly him, but I’ll never admit it 😀 ) came up with the idea of using Datamarts as staging area and using Dataflows afterwards to enable Incremental Refresh. With this workaround, we’ll have an Azure SQL DB (this is technically a Datamart behind the scenes) as staging area, and therefore Incremental Refresh will work as Query folding will be possible! Denis already wrote a great article how to set it up for the Power BI Log Files, which only holds the last 30 days. Check it out here: https://whatthefact.bi/power-bi/power-bi-datamart/persisting-temporary-accessible-data-via-power-bi-datamarts-with-the-example-of-power-bi-activity-logs/ In my blog post I’m going to use a SharePoint site to test at the end the different scenarios (deleting, modifying, and adding new data). I just want to highlight one more time: This approach will work with any Data Source that Power Query / Datamart can connect to. So, it will also work with Excel Sheets, CSV files, BLOB, etc. What a game changer!
What is this Incremental Refresh, Query Folding, and why should I care?
Usually, if you connect to a data source with Power BI – and once your transformation and modelling is done – you set up an automatic refresh of the dataset. The beauty of this is, that all data will be refreshed every time. That works perfectly fine for small datasets. But what if you wish to only update the last few days because there is no need to refresh data from last years as those data never changes? For example, a sales report showing my sales from 2012 – 2022. Sales coming from the years 2012 – 2021 do not change usually so there is no need to update them on a regular base therefore we’re looking for a way to update only the last 7 days of 2022 in this example. This will speed up the Dataset refresh and that’s exactly what Incremental Refresh does. As creator of a dataset, you can set up how many days, months, or years you wish to refresh and everything older than that should just be stored. More insights about Incremental Refresh can be found here: https://docs.microsoft.com/en-us/power-bi/connect-data/incremental-refresh-overview
And how does Query Folding plays a role in this whole setup? Because we configure a specific date in our refresh (in our example we wish to refresh only the last 7 days of 2022), this date has to be provided somehow to the data source. If we’re talking in SQL, this means there has to be somewhere a WHERE clause filtering the data to the last 7 days. While Power BI connects to the data source, it tries to create Queries in the data source language (so if we connect to a SQL DB, it will talk SQL) and on top it tries to push all the different transformations that we did in Power Query to the data source. Again, as an example, if we rename a column from “Column A” to “Revenue” and our data source is SQL, it will generate something like SELECT [Column A] as [Revenue] so that SQL does the transformation. This is exactly what Query Folding is. It tries to push the transformations down to the data source. My friend and MVP Nikola Ilic did a great blog about Query Folding which you can find here: https://data-mozart.com/what-is-a-query-folding-in-power-bi-and-why-should-i-care/ or if you’re more interested in the Microsoft Docs following this link: https://docs.microsoft.com/en-us/power-query/query-folding-basics
Due to the fact that Incremental Refresh requires Query Folding to be able to get the latest data we’re looking for, not all data sources are supported. As an example, Excel, BLOB, CSV files, can’t be incrementally refreshed until now!
Power BI Datamarts
During Build 2022 in May, Microsoft announced a new artefact called Power BI Datamarts (see https://powerbi.microsoft.com/en-us/blog/democratize-enterprise-analytics-with-microsoft-power-bi/) to democratize enterprise analytics for everyone. With Datamarts, every user has an intuitive no code / low code database solution at hand as behind the scenes, an Azure SQL Database will be created.
A datamart creator can use the no code experience to extract, transform, and load data into a database that is fully managed by Power BI. There’s no need to worry about creating and managing dataflows or data refresh schedules—it’s all automatic. The user gets an intuitive SQL and visual querying interface for performing ad-hoc analysis on the data. Users can then connect to the datamart using external SQL-aware tools for further analysis.
Arun Ulagaratchagan
Therefore, we can connect to any data source, load it into a Datamart, and store it technically in a Database. Because now we have our data in our database, we can connect to it with a Dataflow and set up Incremental Refresh as Query Folding is now supported!
Let’s create a Datamart
As of today, Power BI Datamart is in Public Preview and a Premium feature so Premium, Premium per User, or Embedded is required. In my case I’m going to use a PPU license to create a Datamart. To be able to do so, I log in to PowerBI.com and select my demo workspace PBI Guy. In there, I choose New and select Datamart.

For the purpose of this blog post, I’m going to use a SharePoint list but as mentioned already, you can easily use something else like an Excel Sheet, CSV file, etc.

Therefore, I have to select Get data from another source and choose SharePoint Online list afterwards. Once selected, I provide my SharePoint site and my credentials, select my list, and hit transform data.

In Power Query Online I select only the needed columns (ID, Title, Date, and Revenue) and make sure that all data types are correct. As Incremental Refresh requires a DateTime column, please ensure your date column is set up correctly.

Once done, I select to load the data into my Datamart, and rename it on the next screen to “Staging Datamart” by selecting the arrow at the top.

Next, I create a Dataflow which should connect to my Datamart. Before I do so, I go back to my workspace, select the three dots besides my newly created Datamart, and hit Settings.

In there, I expand Server settings and copy the string.

Now I head back to my workspace, select New, and choose Dataflow.

On the next screen, I select Add new Table, and search for Azure SQL Database.

Once selected, I provide the copied Datamart (Azure SQL) string connection as Server name, select Authentication kind “Organizational account”, and select Next.

On the next screen, I select my table, and check in the Preview window if the data is correct. Once approved, I select Transform data.
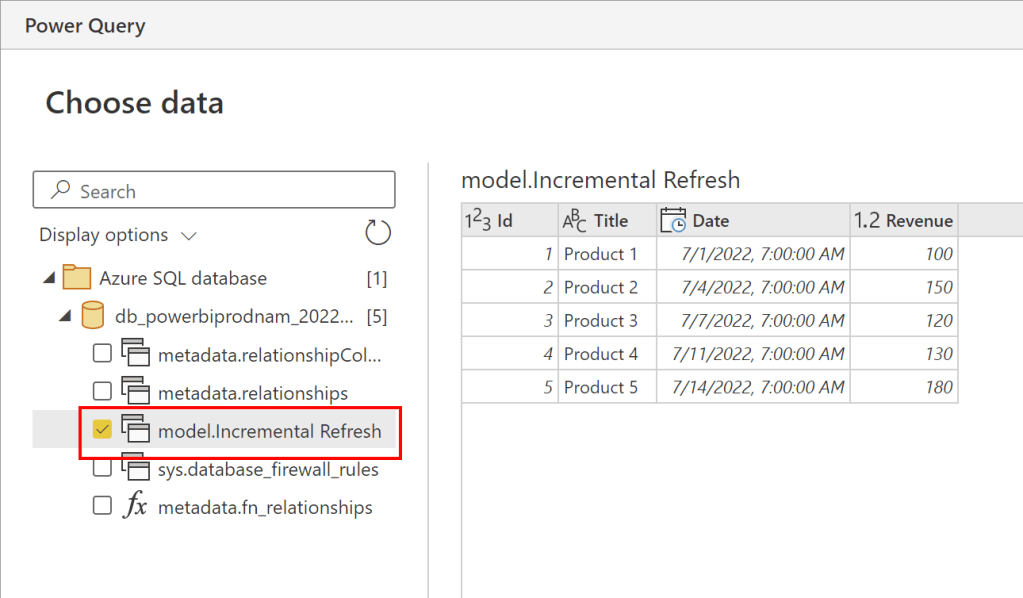
In the Power Query Online experience, I don’t have to adjust anything anymore, but it would be possible if needed. Therefore, I just select Save & close, and save my Dataflow on the next screen with the name “Incremental Refresh”.
As next step, I have to configure Incremental Refresh. Luckily, this is pretty straight-forward. I just select the Incremental Refresh button, turn it on, and choose my Date column within the Dataflow as the DateTime column needed.

Lastly, I configure to store the past 3 years and only refresh the last 7 days. After hitting save I finished the configuration.

Once saved, a window pops up at the top right to Refresh the Dataflow now. I do so by selecting the button Refresh now to load the data into the Dataflow.

It’s time to test
Now that we have set up everything (connecting with a Datamart to our data source, connecting a Dataflow to our Datamart and setting up incremental refresh) let’s test if it works as expected. Today is the 14th of July 2022. In my demo list, I have some sales starting 1st of July until today. If I connect now with Power BI to my Dataflow, I see all five entries coming indirectly from SharePoint – so far so good.

Now, let’s do some changes in the SharePoint list. I will delete two rows, one from the 1st of July and one from the 11th of July. Further, I changed Product 2 name to Product 22 on the 4th of July and updated the Revenue on the 7th. Lastly, I added a new sale for today.

Our first step is now to trigger a refresh for our Datamart. Once the refresh successfully finished, we see a 1:1 copy of our SharePoint list.
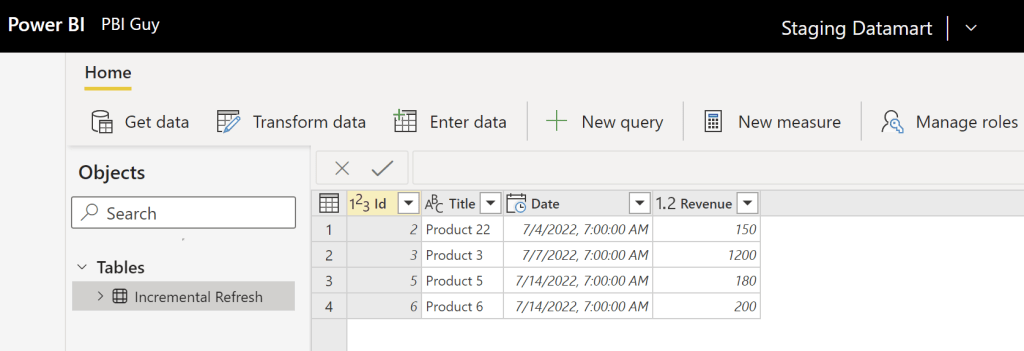
Now, let’s trigger a refresh of our Dataflow. Once it’s finished, I hit the refresh button in my Power BI Desktop, which is connected to the Dataflow, to see the end result.
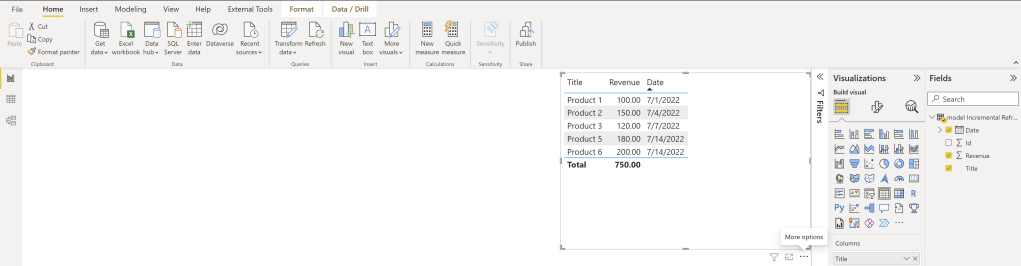
And as expected, Product 1 and 2 haven’t changed! So, we have now some historization in Power BI – awesome! But let’s analyze each row to understand the behavior.
Because we set up the Incremental Refresh to refresh only the last 7 days, everything prior to it will be ignored. Because Product 1 and 2 are older than 7 days, the changes didn’t affect our data in the Dataflow. But what about Product 3 which is dated 7th of July? This is, from an Incremental Refresh Point of view, 8 days ago because
- 14. July = Day 1
- 13. July = Day 2
- 12. July = Day 3
- 11. July = Day 4
- 10. July = Day 5
- 09. July = Day 6
- 08. July = Day 7
and therefore, 7th July hasn’t been updated neither in our refresh. Product 4, which was dated on the 11th of July, has been removed – this is as expected. And lastly, our newest sale from today has been added (Product 6) which is also as expected.
Great, this is a real game changer as with Power BI you can now create a real staging area, and on top use Incremental Refresh to historize your data! But keep in mind, with this approach the data will only be available in the Dataflow. I would highly recommend using at least your own Azure Data Lake Storage Gen2 to store the Dataflow into it (see https://docs.microsoft.com/en-us/power-bi/transform-model/dataflows/dataflows-azure-data-lake-storage-integration). This way, you can access and enhance it if needed. Further, you can do backups and make sure it will not be lost if you delete your Dataflow.
Please let me know if this post was helpful and give me some feedback. Also feel free to contact me if you have any questions.
If you’re interested in the files used in this blog check out my GitHub repo https://github.com/PBI-Guy/blog

Hello, I can’t grasp why you set up incremental refresh for dataflow that gets data from Datamart instead of setting it up for Datamart itself?
LikeLike
Hey Sergiy
Incrememtal Refresh doesn’t work on any data source. E.g. Excel or CSV. SharePoint would work as OData is supported, but I wanted to show how you can build a workaround just in case it isn’t. I used SharePoint in my example just because it was the easiest and fastest data source for me (no Gateway, no conplicated Authenticazion, etc.). Hope that helps.
LikeLike
I can get this to work using a SharePoint Folder/Excel source but not JSON. I tried both SharePoint Folder and Azure Blob Container combining <10 .json files. The datamart part works fine. However the dataflow, which is created successfully, fails on the refresh "Error: PipelineException: Internal connection fatal error."
Any ideas?
LikeLike
Hi Gary
Can you elaborate on your error message a little bit more trying for example just to connect with a Dataflow to the Datamart and try to refresh it? If that works, set up the DateTime column and try to refresh again. If that works, try to set up Incremental Refresh. This way you can really understand where exactly the error occurs and try to solve it. A good support source is also the Power BI Community website –> https://powerbi.microsoft.com/en-us/support/
LikeLike
Hi,
In this specific example, why not use the Azure Cost management connector directly from Power BI desktop. It will allow you to get as much history on Azure cost as you want.
Billing reader authentication is required though.
/Chris
LikeLike
I don’t think you can extract historic data as much as you want as usually Microsoft stores for a max of 90 days your data (GDPR). That’s the reason why a historization is required, and with this approach you can do it by only using Power BI.
LikeLike
But the datamart itself still has to do a full load each time. There’s no way to get around that. I guess the benefit is you can centralise the full load and have multiple dataflow consumers doing incremental load. So at least the full load only occurs once in the datamart as opposed to for every single dataflow using report.
LikeLike
Yes, that’s true that the Datamart has to do a full load. I see it as you: You can than benefit from using one (or multiple) Dataflow(s) on top and create incremental refresh.
LikeLike
Infact there is an easy work around,
Hope this is much simpler to the suggested process.
Please provide comments
LikeLike
Ok, then you can not reduce total refresh time with this technique
LikeLike
Wouldn’t i need to setup a datamart refresh and dataflow refresh (schedule refresh) as well? (or you’re skipping this step as of datasource is sharepoint?)
is it possible just to configure a datamart incremental refresh? and then consume dataset created from datamart?
LikeLike
Hi Michel
Yes, you would need to setup a Dataflow and Datamart refresh. Regarding the second question, you would be able to do that in this case with SharePoint as OData supports incremental refresh. But in a case where Inc. Refresh is not supported (e.g. Excel), you would need to set up a staging Datamart and on top a second Datamart which connects to the first one configuring Inc. Refresh.
Hope that help 🙂
Greets
LikeLike
This is a great post – really helpful and seemed to be exactly what I was looking for but I have been unable to make it work for my particular use case and I can’t figure out why.
My scenario is this. I have a data source consisting a bunch of spreadsheet on a website. Once a week I need to download the data from these and incrementally add it to all previous weeks’ data.
So I set up a datamart an use Power Quert to download the contents of the lates set of spreadsheets. I then add a column with DateTime.LocalNow() to create the datetime stamp required for the incremental loading. This will always be the last time the datamart was refreshed.
I then load this data into a dataflow with incremental load set up.
I would expect that each time the data is refreshed it would add the complete contents of the new download to the existing contents (since the timestamp will always be different). However, the result I get is always just the last refresh data,
Any advice would be very gratefully recieved.
LikeLike
Hi Ian
Thanks for your question and your patience. Right now it’s a crazy time and I just couldn’t answer earlier…
Regarding your issue, I’m not sure exactly where it is as it sounds to me that you set up everything right. Did you configure your inc. refresh to store the last x days/months/years? Can you try out a second Datamart connecting to the first one instead of a Dataflow?
LikeLike
The post is really helpful to start setting up incremental refresh with excel file/csv file source. My scenario is slightly different. Our OLTP system generates data to Outlook inbox periodically as excel file attachments which are extracted and saved into the shared drive. Excel files for the current financial year is updated by a vba code which extracts the attachment and appends the data to the current financial year data.
Any guidance on setting up incremental refresh when I use folder source to load excel files into power query from your end would be extremely helpful. Thanks in advance.
LikeLike
If I understood it correctly, I would do it as following:
1. Save Excel File into folder
2. Load Excel file to Datamart 1. Create a Filter to read only the latest file (e.g. get max date and filter on it or use order by and top 1). Make sure you have a date column in your Datamart which will be used for inc. refresh.
3. Create Datamart 2 connected to Datamart 1 and set up incremental refresh
Hope it helps
LikeLike
Infact there is an easy work around,
Hope this is much simpler to the suggested process.
Please provide comments
LikeLike
Hi
Thanks for the proposed solution. This is def. true as with Fabric a lot of things are nowadays easier 🙂
Thanks and greets
LikeLike