Working with Data Scientist I got quite often the question if Power BI is able to trigger a Python (or R) script to recalculate scenarios and show the result more or less immediately in Power BI again. On top it would be great to be able to pass parameters from Power BI to Python so an user can influence the script. As you guessed it right – because I’m writing this blog post – it is possible! But not purely with Power BI but rather in combination with other (Microsoft) services.
First things first
Before I deep dive into a solution, I want to make sure a common understanding of the issue is given. First of all, Power BI is a reporting tool. As such, it relies on data sources to be able to connect to some kind of table and visualize the result. It is a purely “read-only” visualization and not a “writeback” tool. Therefore having some kind of input mechanism, to be able to pass parameters to a Python script in our case, does not work with purely Power BI.
Further and as already mentioned, it has to connect “to something”. This means we can not execute a Python script on the fly and check the result. Yes, you can use Python in a visual and do some kind of visualization on the fly, but that’s in most cases not sufficient as just a few libraries are supported (https://learn.microsoft.com/en-us/power-bi/connect-data/service-python-packages-support). Yes, you can also have Python as Data Source, but to be able to recalculate a new scenario you would need to refresh the Dataset every time. Imagine multiple users accessing the same report and one of them is triggering a Dataset refresh – this will for sure lead to confusion for other users if the data changes while accessing the report. Therefore we’re looking for a way to independently run a script, store the result in a way Power BI can access and show it in near-real time, and on top pass parameters from Power BI to the script.
Which services to choose
Let’s go step by step and see which service we can use. First of all, we need a Python script. As you probably have noticed, I’m a big fan of Azure Synapse so let’s use the Notebooks from there and write our Python code in PySpark. The result has to be stored somewhere so Power BI can access it in near-real time. This means the data source has to support DirectQuery, otherwise we would need to refresh the Dataset every time the script runs. Thus, Azure SQL dedicated pool would be a great choice, but on the other hand I would need to make sure it’s running while users are accessing the report. So I’ll focus on a more cost-effective way and try to use SQL Serverless. As you can connect to files through SQL Serverless and run SQL queries on top, I will save the result from my Python script as parquet files in my Azure Data Lake Storage Gen2.
Next, I have to make sure my Python script can be executed whenever needed. This requirement can be fulfilled by using Synapse Pipelines. This way I can call the Synapse Pipeline REST API and trigger a run whenever needed. Further, Synapse Pipelines can be parametrized and those parameters can be passed further to the Python script. On top, I can also pass the Pipeline Parameters through the REST API – perfect!
As a last step, I need some kind of input mechanism in Power BI to be able to influence the parameters and trigger a Synapse Pipeline run. For such scenarios, Power Apps is the right choice! Microsoft offers an out-of-the-box visual which can be used to integrate a Power Apps app providing input fields. Further, a button can be defined which will trigger a REST API call or – even better and more scalable – trigger a Power Automate flow which will trigger the Synapse Pipeline.
Here’s an overview of all the services mentioned and used in this solution:
- Power BI
- Power Apps
- Power Automate
- Azure Synapse
- Synapse Pipeline
- Synapse Notebook
- Azure Data Lake Storage Gen2
- SQL Serverless Pool
The main idea of this blog post is to showcase that, in general, it is possible to trigger a Python (or R) script from Power BI. Looking from a performance point of view, I wouldn’t choose Synapse Pipelines but rather Azure Functions as it will execute the Python script much faster. Further, in a production environment, I would store the result in a SQL Dedicated Pool (or Azure SQL) and not go through the Serverless one as the performance can be influenced much better rather then connecting to parquet files. Lastly, creating multiple, small parquet files in ADL Gen2 is also not considered as best practice but rather creating fewer but bigger files. On the other hand going through Synapse Pipelines showcase the scalability of the whole solution.
Let’s roll up our sleeves and get started
Let’s start by creating a simple Python script which takes two numbers as parameter and add them up. Because the report will be used by multiple users at the same time, I have to make sure on one hand that the different calculated scenarios will be stored properly and on the other hand users will identify their scenario. For that reason I create three more parameters for User Name, UPN, and timestamp. Those parameters have to be influenced from outside as they are changing depending on the user. But before defining the parameters, I also add the necessary libraries.
#Import necessary tables
from datetime import datetime
import pandas as pd#Define standard parameters which can be called from outside
firstNumber = 7
secondNumber = 1
user = 'Chewbacca'
upn = 'chewbacca@kbubalo.com'
timestamp = datetime.now()
timestamp_string = timestamp.strftime('%Y_%m_%d_%H_%M_%S')In my next block of code I define further parameters which should not be influenced from outside. This includes my ADL Gen2 storage account, my container, folder, and file name. I decided to create a folder for each user in which each scenario should be saved to be able to differentiate between the users.
adlgen2 = '...'
container = 'dev'
folder = '15 Demo/Trigger Python from Power BI via Power Platform/' + user
fileName = 'Scenario'Next, I create a DataFrame to store the parameters as well as the result (adding number 1 and 2).
#Create dataframe with provided data
d = {'firstNumber': [firstNumber], 'secondNumber': [secondNumber], 'result': [firstNumber + secondNumber], 'user': [user], 'upn': [upn], 'timestamp': [timestamp]}
df = pd.DataFrame(data=d)Lastly, I store the DataFrame as parquet file in my configured ADLS Gen2.
#Store Dataframe as parquet file
df.to_parquet('abfss://' + container + '@' + adlgen2 + '.dfs.core.windows.net/' + folder + '/' + fileName + '_' + timestamp_string + '.parquet')To make sure my defined parameters can be influenced “from outside” (this means form Synapse Pipeline in this case), I have to mark them as such. Therefore I select the three dots to the block of code and select Toggle parameter cell.

If done correctly, you’ll see a “Parameters” in the bottom right corner of your code block.

Once done, let’s test the script by running it and check if a parquet file is created as wished – looks good! A parquet file is created in my ADLS Gen2 and the result is as expected.

My next step is to create a Pipeline and pass parameters from the Pipeline to my Notebook. In Azure Synapse there is a small icon at the top right to automatically create a Pipeline out of your notebook. I just select it and hit New Pipeline.
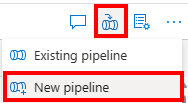
The Azure Synapse Pipeline window will open up. I rename my Pipeline to “PBI Guy Trigger Python” and add 4 Parameters by hitting the + New in the Parameters section of the pipeline. Make sure you’re not selecting the Notebook but the Pipeline. I name my parameters like the one in the Notebook and give them a proper type as well as a default value because I want to test my pipeline afterwards making sure the parameters are passed.
The Parameter name do not have to match the names from my Python code but it makes sense to name them the same way.

Next, I select the Notebook activity, choose Settings tab and expand Base parameters. Again, I add 4 parameters and assign the correct type to them. Keep in mind, these parameters have to match exactly with the names from your Python Notebook. Once done, I select Add dynamic content and select my Pipeline Parameter to the corresponding Parameter and hit ok.

Once done, let’s test the Pipeline as well by hitting “Debug” at the top. If wished, you can change your parameters now as a Pane will pop up on the right hand side of your screen. I just confirm by clicking OK. After roughly 3 minutes in my case the Pipeline run successfully and I see a folder with my name including a parquet file has been created. By right-clicking on it and selecting New SQL Script – Select TOP 100 rows I can check the result making sure my parameters has been used in thy Python script – looks good so far! Don’t forget to publish the Pipeline now.

Now, I have to trigger the Pipeline through the REST API. Luckily, Microsoft provides a great documentation here which highlights the REST API call. As we see it’s a POST call to {endpoint}/pipelines/{pipelineName}/createRun?api-version=2020-12-01. {endpoint} in this case means the Development endpoint of my Azure Synapse workspace which can be found in Azure Portal by selecting the workspace in the overview section. You can easily copy it by selecting the copy button right next to it.

To trigger the Pipeline through the REST API I’ll create a Power Automate flow which will be triggered from Power Apps. As I wish to connect the Power BI Dataset with my Power Apps app I have to start in Power BI and create a report on top. For that, I just open Power BI Desktop, create a dummy table by entering a random number into the table, and add the Power Apps Visual. If you need a step-by-step guidance how to create a Power Apps starting in Power BI check my previous blog post here: https://pbi-guy.com/2021/11/17/show-secured-images-in-power-bi/ It will walk you through the most important steps. Further, I’ll focus on connecting to the right data in a later stage therefore the dummy table.
If you have issues in Power BI Desktop and the Power Apps app won’t load try it in the Service. You can easily publish the empty report and modify it from the browser. Once done, you can download the PBIX file again.
Once done, I just add my dummy column into the fields section and hit Create New in the Power Apps visual. This will open a the Power Apps studio where you can create your app. I will not walk you through on each step how I created my app but rather focusing on the most important parts on a high level. If you’re interested in the final solution, you can check my GitHub repo.
I add two Text Input objects as well as two labels making clear what the input should be. Further, I add a button which will trigger a Power Automate flow and provide the values from the Text Input fields as parameters to the flow. Once added, I rename each object making sure each one of them has an appropriate name – this will help me referencing it later on.

In the screen shot above you’ll see some further objects. Those are added to make the app more appealing and are not crucial for the whole process.
Next, I select the button and make sure the OnSelect property is active (see red box), head over to Power Automate on the navigation pane, hit Create new flow and select + Create from blank.
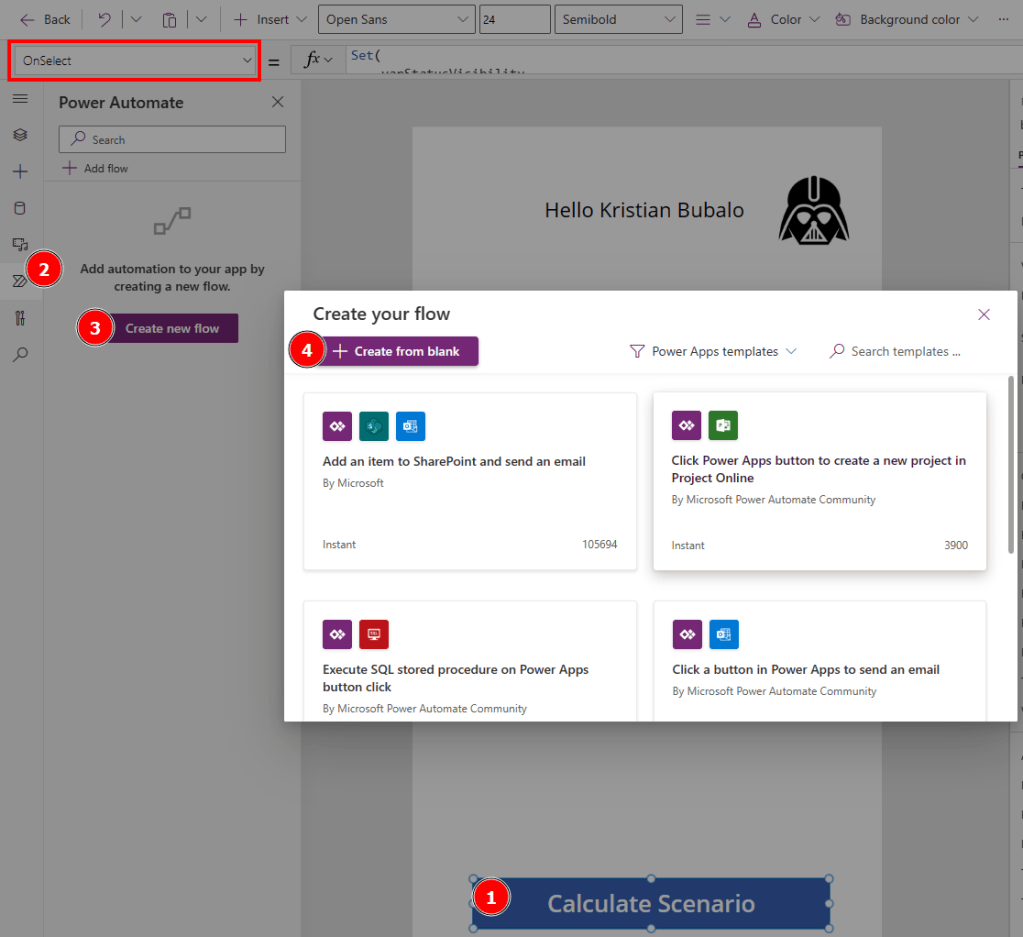
A new pop up window will appear where a flow can be created. Again, I will not walk you through the whole process of creating the flow but rather focusing on the most important steps. A step-by-step guide how to create a flow and to familiarize yourself with it can be found in one of my previous blog posts here.
The first thing I do is to specify all needed variables. As I wish to call the REST API with a Service Principal, I create one in the Azure Portal (how to create a Service Principal can be found here), give no API permission but rather add the Service Principal as Synapse Credential User in the Synapse Portal (see Synapse RBAC roles for further details about permissions).

Therefore, I create following variables in my flow:
- Tenant ID
- Client ID
- Audience for Azure Synapse (can be found in the documentation here)
- Azure Synapse Development Endpoint
- Synapse Pipeline Name (this is the name of the Pipeline, in my case PBI Guy Trigger Python)
I also specify an action to get the secret of my Service Principal from Azure Key Vault as I have stored my secret there. Otherwise you can also just store it in a variable but this is not the recommended way.
As a next step I add a HTTP request which looks like following:
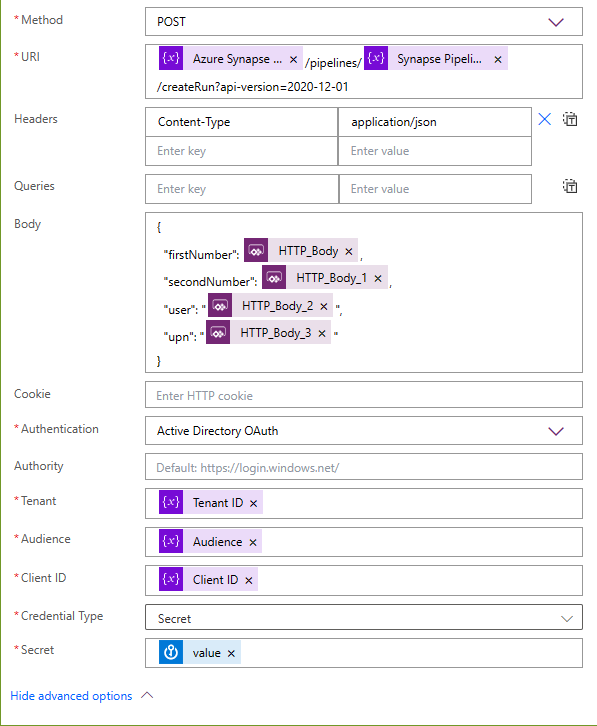
I choose POST as Method, put in the REST API URI but replace the hardcoded parameters with my variables from the previous steps. In the body I specify my Pipeline Parameters. To get them from Power Apps, I place my cursor to the right position and select from Dynamic content “Ask in PowerApps”. This will create automatically the necessary dynamic content. As Authentication I choose Active Directory OAuth and provide the necessary variables.

This is already enough to trigger our Synapse Pipeline. Now, we just have to provide the input from Power Apps input fields to the Power Automate flow. So let’s save our flow, select the button, and on the OnSelect property specify what should happen. We can reference to the flow by name and select Run as attribute. In the brackets we can now add values to the variables we specified in the body of our HTTP action in the flow. To do so just reference to the input object and add Text as attribute. On top I’m using the out of the box User object to provide the full name and email. In my case the code looks like following.

'PBIGuy-TriggerPythonfromPowerBI'.Run(
txtinp_number1.Text,
txtinp_number2.Text,
User().FullName,
User().Email
)Now let’s test it by running the app, provide some numbers and hit the button. If everything is set up correctly, the flow as well as the Synapse Pipeline will run successfully. In my case it took roughly 1 minute and I can see the result in my ADLS Gen2. This is great! As everything works I save and publish my app.

To make the app more user friendly, I modified the flow further to call the REST API to get a current status of the Synapse Pipeline. I do a loop until the Pipeline gives a Succeeded message which I give back as response to the Power Apps app. On top I’m using a loading gif while the whole flow is running. Once finished, the gif will disappear and I trigger a Dataset refresh making sure the latest data will be loaded.
Note that your Service Principal needs additional permission to be able to read the status through the REST API, for example the Synapse Monitoring Operator.
One of my last steps is now to connect the dots with Power BI. Through SQL Serverless Pool I can read parquet files with the OPENROWSET statement, but this is not supported with Power BI. As we need a way through DirectQuery to access the files, I create an External Table in my SQL Serverless Pool by just going to my file, right click on it, select New SQL script, and choose Create external table.

In the pane on the right hand side I select to continue. Afterwards I configure in which SQL Pool as well as which database my external table should be created, give it a name, and choose “Using SQL script” to get the full control of the script.
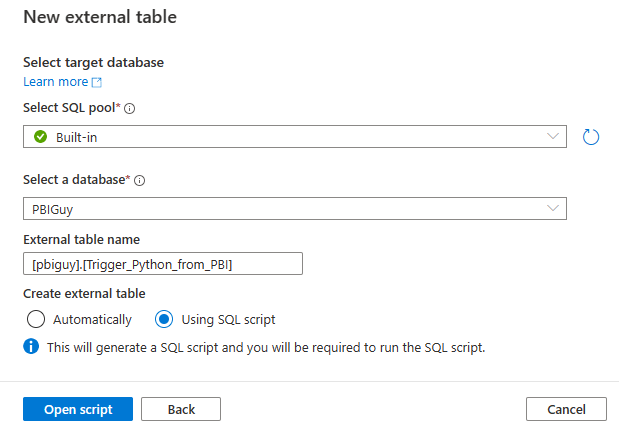
As I haven’t created the pbiguy schema yet, I just add a line of code to do so. Further, I modify the location to not point to a single file but rather to the overlaying folder by adding two * at the end.

If everything worked as expected you will get a table with all scenarios for all users so far.

Now we can connect with Power BI through the SQL Serverless Endpoint. This one can be found in the Azure Portal in the overview of our Synapse workspace.

Back in Power BI Desktop I select Azure Synapse Analytics SQL, configure the connection, choose DirectQuery, and paste a SQL Statement to select all columns and rows. Once done, I create a simple table visual right to the Power Apps visual. This way we can make sure the scenario will be visible once the whole process has finished. Now let’s do a final test and provide some data and calculate our scenario. Once I add some numbers and hit the button, I have to wait till my process has finished. In my version I added a rocket as gif to indicate the process is running (see comment above).

Once done, I see immediately the result in my table!

That’s it, it works! This way multiple users can access the same report, calculate their scenarios and through filter options (or even with RLS) you can make sure that each user can select his or her scenario.
Some last thoughts
As much as I love the whole solution there are still some things to consider. As written above, the main idea was to prove that from Power BI you can trigger a Python (or R) script and get the result back in near-real time. With Azure Synapse you have unlimited scalability. On the other hand it takes quite long to process the whole request and the bottle neck is the Synapse Pipeline. If you, like me, add a “Respond to a Power Apps” action at the end of your Power Automate flow, it could be that you get an error in the app if the flow runs longer than 120 seconds (this is the timeout limit of the action) like the one below.

Especially if you run it for the first time, Synapse Pipeline will take longer as it has to spin up. Therefore I would suggest to try Azure Functions as I’m expecting a much faster process time.
Further and as well mentioned at the beginning, instead of storing individual and multiple small parquet files, I would rather store it directly into an Azure SQL DB.
Please let me know if this post was helpful and give me some feedback. Also feel free to contact me if you have any questions.
If you’re interested in the files used in this blog check out my GitHub repo https://github.com/PBI-Guy/blog
