In this mini series I’m walking you through how to extract data from the Fabric Metrics App to, for example, create a monthly chargeback report based on it. In my last blog post, I showed how to trace the required DAX Statement. In the second part, I will show how we can use Microsoft Fabric Notebooks and the DAX statement from Part 1 to extract the data and store them into OneLake. For that, I’ll follow the medallion Architecture (Bronze – Silver – Gold) to store and prepare the data.
Prerequisites
For this solution we need following services and licenses:
- Microsoft Fabric or Power BI Premium Capacity
- Workspace in a Fabric / Premium capacity
- Lakehouse
- Notebook
- Python Skills
Let’s get started
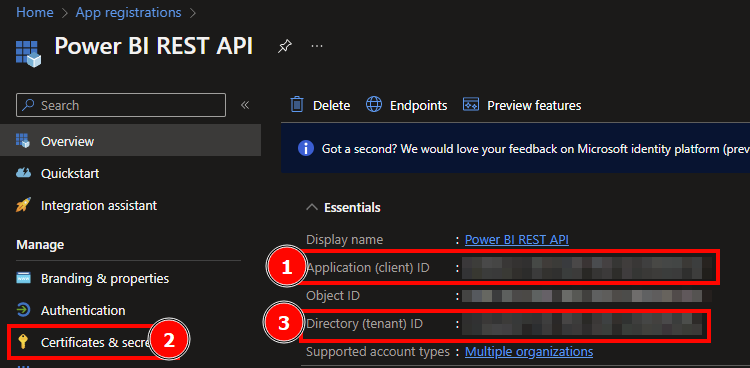
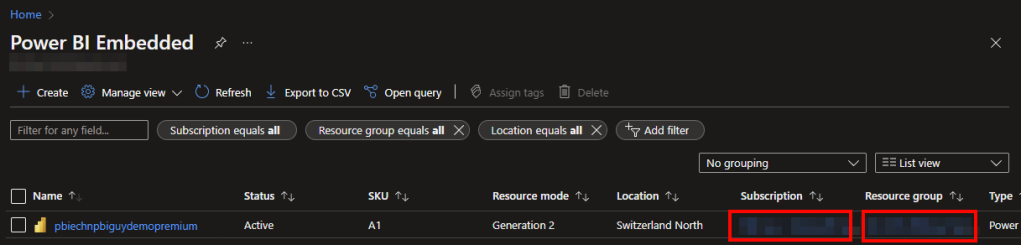
My first action is to create a new Lakehouse in the Microsoft Fabric Capacity Metrics workspace which I call “FabricMetricsApp”. This will be used to store the output of the Metrics App. Important for this approach: create it in the Metrics App workspace as we’re going to connect to the Semantic Model via Python to it with Semantic Link.

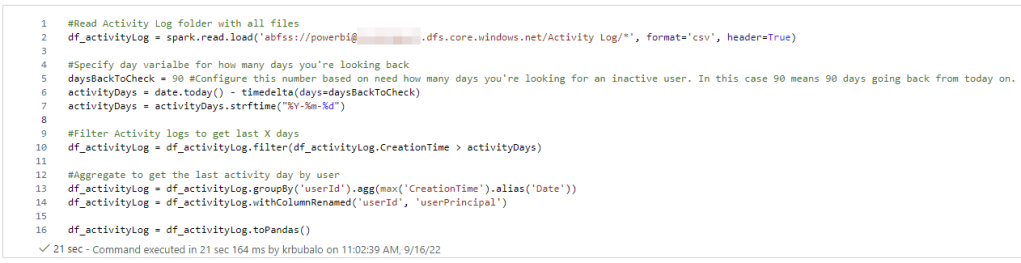
Next, I create a Notebook and as usual, I import the required libraries. On top, I also set the spark configuration following best practices. As bonus, I also configure the Power BI Catalog. This way, I can write SQL Statements on top of my Semantic Model if needed!
#Import required libraries
%pip install semantic-link
%load_ext sempy
import pandas as pd
import sempy.fabric as fabric
from datetime import date, datetime, timedelta
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, FloatType, TimestampNTZType
spark.conf.set("sprk.sql.parquet.vorder.enabled", "true")
spark.conf.set("spark.microsoft.delta.optimizeWrite.enabled", "true")
spark.conf.set("spark.microsoft.delta.optimizeWrite.binSize", "1073741824")
spark.conf.set("spark.sql.catalog.pbi", "com.microsoft.azure.synapse.ml.powerbi.PowerBICatalog")My next cell defines the required parameter. Here, I’m giving the Semantic Model (dataset) name, which is the given name of the Fabric Metrics App. The Semantic Model has different tables and one of them is called “Capacities” which lists all the capacities in the environment to which I have access to. This way, I could also loop through all capacities to extract the required data. Further, I’m defining a timepoint start date which is dynamically yesterday’s date. I’m also defining a bronze, silver, and gold layer files structure and add a DataFrame Schema at the end.
#Define required parameters
dataset = 'Fabric Capacity Metrics' #Default name of the Semantic Model
talbe_name = 'Capacities' #Table Name to get all Capacities
today = datetime.today() #Get Today's date
timepoint_start = today - timedelta(days=1) #Get yesterday's date on which we will extract all details
path_bronze = 'Files/01 Bronze/'
path_silver = 'Files/02 Silver/'
path_gold = 'Files/03 Gold/'
dataframe_schema = StructType([
StructField("BillingType", StringType(), nullable=True),
StructField("Status", StringType(), nullable=True),
StructField("OperationStartTime", TimestampNTZType(), nullable=True),
StructField("OperationEndTime", TimestampNTZType(), nullable=True),
StructField("User", StringType(), nullable=True),
StructField("Operation", StringType(), nullable=True),
StructField("OperationID", StringType(), nullable=True),
StructField("WorkspaceName", StringType(), nullable=True),
StructField("Item", StringType(), nullable=True),
StructField("ItemName", StringType(), nullable=True),
StructField("TimepointCUs", FloatType(), nullable=True),
StructField("DurationInS", IntegerType(), nullable=True),
StructField("TotalCUInS", FloatType(), nullable=True),
StructField("Throttling", IntegerType(), nullable=True),
StructField("PercentageOfBaseCapacity", FloatType(), nullable=True),
StructField("capacityId", StringType(), nullable=True),
StructField("Timepoint", TimestampNTZType(), nullable=True),
StructField("OperationType", StringType(), nullable=True)
])In my third cell, I get all the capacities from the Semantic Model.
#Get all capacities
df_capacities = spark.sql("""
SELECT c.capacityId
FROM pbi.`""" + dataset + """`.Capacities c
""")For testing purposes, I’m filtering the capacities down to just one in my next block of code. If you wish to get through all of your capacities, just remove the filter statement (line 3).
#For testing purpose filtering it down to only one capacity
capacity_id = '...'
df_capacities = df_capacities[df_capacities['capacityId'] == capacity_id]
display(df_capacities)As next step, I create two functions – one for the background and one for the interactive operations – for reusability purpose. As this piece of code is quite huge, let me split it up in smaller junks.
First, I define the function for the background operation. The function itself requires two parameters – date and Capacity ID. I also add a small description of the function to document it.
def generate_dax_background_operation(date_today, capacity_id):
"""
Generate the DAX statement which is used to get the background operations of the Metrics App for a given Capacity and day.
Arguments required:
date_today (datetime) - Date on which the background operation should be extracted
capacity_id (string) - Capacity ID on which the background operation should be extracted
Returns:
DAX Statement (string)
"""Next piece of code is to set the right starting timepoint. For that, I use the input parameter and set it to midnight. As I just want to test the code for a few timepoints, I’m replacing the timepoint_start with a hardcoded date. Obviously, this piece of code should be deleted.
#timepoint_start = date_today.replace(hour=0, minute=0, second=0, microsecond=0) #Set timepoint to the beginning of the day
timepoint_start = date_today.replace(day=25, month=3, year=2024, hour=16, minute=54, second=00, microsecond=00) #Use this timepoint to get a specific one - used for testing purpose
timepoint_next = timepoint_start
i = 0 #Initialising iteration count to check if all timepoints (2880 in total for a day) has been coveredMoving on, I need now a loop to go through from the first timepoint to the last one of the day. My logic checks if the current timepoint is still on the same day as the initial timepoint and if so, it will proceed. Again, as I’m just interested in a few timepoints, I hardcoded until when the loop should work. Lastly, I extract and convert the timepoint details like year, month, etc. into a string as I’ll need them later on.
#while timepoint_next.day == timepoint_start.day: #As long as the day of the next timepoint is the same as start timepiont, loop will continue and add 30seconds at the end
while timepoint_next <= datetime.strptime('25.03.2024 16:56:00', "%d.%m.%Y %H:%M:%S"): #Use this filter to get some specific timepoints only - used for testing purpose
current_year = str(timepoint_next.year)
current_month = str(timepoint_next.month)
current_day = str(timepoint_next.day)
starting_hour = str(timepoint_next.hour)
starting_minutes = str(timepoint_next.minute)
starting_seconds = str(timepoint_next.second)My next parameter defines the DAX statement for the background operations. I’m making it as dynamic as possible to get the right data for the right timepoint. Remember, the DAX Statement was defined in the first part of this series.
dax_background_operation = '''
DEFINE
MPARAMETER 'CapacityID' = "''' + capacity_id + '''"
MPARAMETER 'TimePoint' = (DATE(''' + current_year + ''', ''' + current_month + ''', ''' + current_day + ''') + TIME(''' + starting_hour + ''', ''' + starting_minutes + ''', ''' + starting_seconds + '''))
VAR varFilter_Capacity = TREATAS({"''' + capacity_id + '''"}, 'Capacities'[capacityId])
VAR varFilter_TimePoint =
TREATAS(
{(DATE(''' + current_year + ''', ''' + current_month + ''', ''' + current_day + ''') + TIME(''' + starting_hour + ''', ''' + starting_minutes + ''', ''' + starting_seconds + '''))},
'TimePoints'[TimePoint]
)
VAR varTable_Details =
SUMMARIZECOLUMNS(
'TimePointBackgroundDetail'[OperationStartTime],
'TimePointBackgroundDetail'[OperationEndTime],
'TimePointBackgroundDetail'[Status],
'TimePointBackgroundDetail'[Operation],
'TimePointBackgroundDetail'[User],
'TimePointBackgroundDetail'[OperationId],
'TimePointBackgroundDetail'[Billing type],
'Items'[WorkspaceName],
'Items'[ItemKind],
'Items'[ItemName],
varFilter_Capacity,
varFilter_TimePoint,
"Timepoint CU (s)", SUM('TimePointBackgroundDetail'[Timepoint CU (s)]),
"Duration (s)", SUM('TimePointBackgroundDetail'[Duration (s)]),
"Total CU (s)", CALCULATE(SUM('TimePointBackgroundDetail'[Total CU (s)])),
"Throttling", CALCULATE(SUM('TimePointBackgroundDetail'[Throttling (s)])),
"% of Base Capacity", CALCULATE(SUM('TimePointBackgroundDetail'[% of Base Capacity]))
)
EVALUATE SELECTCOLUMNS(
varTable_Details,
"BillingType", [Billing type],
"Status", [Status],
"OperationStartTime", [OperationStartTime],
"OperationEndTime", [OperationEndTime],
"User", [User],
"Operation", [Operation],
"OperationID", [OperationId],
"WorkspaceName", [WorkspaceName],
"Item", [ItemKind],
"ItemName", [ItemName],
"TimepointCUs", [Timepoint CU (s)],
"DurationInS", [Duration (s)],
"TotalCUInS", [Total CU (s)],
"Throttling", [Throttling],
"PercentageOfBaseCapacity", [% of Base Capacity]
)'''
Next, I want to evaluate the DAX statement and store the result into a DataFrame but only if the DataFrame is not empty and therefore having some results. I’m not interested in storing empty files. To make sure I can identify the capacity, timepoint, and operation type, I’m adding those fields to the DataFrame. Afterwards, I define the filename by using the timepoint name and save the result into OneLake using the date as subfolder name. This way I’m partitioning it already by day. Lastly, I add 30 seconds to the timepoint as Microsoft Fabric timepoints are calculated in 30 seconds junks and add a 1 to my i parameter to count how many runs have been made. This way, I can make sure that all timepoints have been evaluated.
As a timepoint consists of 30 seconds, a day has 2880 timepoints (2 timepoints per minute * 60 minutes * 24 hours = 2880)
df_dax_result = fabric.evaluate_dax(
dataset,
dax_background_operation
)
df_dax_result['capacityId'] = capacity_id
df_dax_result['Timepoint'] = timepoint_next
df_dax_result['OperationType'] = 'background'
#Set path and file name
subfolder = str(timepoint_next.date()) + '/'
file_name = timepoint_next.strftime("%H-%M-%S")
#Convert Fabric DataFrames into Spark DataFrames
df_dax_result_spark = spark.createDataFrame(df_dax_result, schema=dataframe_schema)
#Save DataFrames to OneLake
df_dax_result_spark.write.mode("overwrite").format("parquet").save(path_bronze + 'Background Operation/' + subfolder + file_name)
#Don't change timepoint intervals, as 30sec intervals are given
timepoint_next = timepoint_next + timedelta(seconds = 30)
i = i + 1
return iTo make sure the code is probably copied, here is the full cell.
#Create a function to get Background Operations of the Metrics App
def generate_dax_background_operation(date_today, capacity_id):
"""
Generate the DAX statement which is used to get the background operations of the Metrics App for a given Capacity and day.
Arguments required:
date_today (datetime) - Date on which the background operation should be extracted
capacity_id (string) - Capacity ID on which the background operation should be extracted
Returns:
DAX Statement (string)
"""
#timepoint_start = date_today.replace(hour=0, minute=0, second=0, microsecond=0) #Set timepoint to the beginning of the day
timepoint_start = date_today.replace(day=24, month=4, year=2024, hour=9, minute=00, second=00, microsecond=00) #Use this timepoint to get a specific one - used for testing purpose
timepoint_next = timepoint_start
i = 0 #Initialising iteration count to check if all timepoints (2880 in total for a day) has been covered
#while timepoint_next.day == timepoint_start.day: #As long as the day of the next timepoint is the same as start timepiont, loop will continue and add 30seconds at the end
while timepoint_next <= datetime.strptime('24.04.2024 09:02:00', "%d.%m.%Y %H:%M:%S"): #Use this filter to get some specific timepoints only - used for testing purpose
current_year = str(timepoint_next.year)
current_month = str(timepoint_next.month)
current_day = str(timepoint_next.day)
starting_hour = str(timepoint_next.hour)
starting_minutes = str(timepoint_next.minute)
starting_seconds = str(timepoint_next.second)
dax_background_operation = '''
DEFINE
MPARAMETER 'CapacityID' = "''' + capacity_id + '''"
MPARAMETER 'TimePoint' = (DATE(''' + current_year + ''', ''' + current_month + ''', ''' + current_day + ''') + TIME(''' + starting_hour + ''', ''' + starting_minutes + ''', ''' + starting_seconds + '''))
VAR varFilter_Capacity = TREATAS({"''' + capacity_id + '''"}, 'Capacities'[capacityId])
VAR varFilter_TimePoint =
TREATAS(
{(DATE(''' + current_year + ''', ''' + current_month + ''', ''' + current_day + ''') + TIME(''' + starting_hour + ''', ''' + starting_minutes + ''', ''' + starting_seconds + '''))},
'TimePoints'[TimePoint]
)
VAR varTable_Details =
SUMMARIZECOLUMNS(
'TimePointBackgroundDetail'[OperationStartTime],
'TimePointBackgroundDetail'[OperationEndTime],
'TimePointBackgroundDetail'[Status],
'TimePointBackgroundDetail'[Operation],
'TimePointBackgroundDetail'[User],
'TimePointBackgroundDetail'[OperationId],
'TimePointBackgroundDetail'[Billing type],
'Items'[WorkspaceName],
'Items'[ItemKind],
'Items'[ItemName],
varFilter_Capacity,
varFilter_TimePoint,
"Timepoint CU (s)", SUM('TimePointBackgroundDetail'[Timepoint CU (s)]),
"Duration (s)", SUM('TimePointBackgroundDetail'[Duration (s)]),
"Total CU (s)", CALCULATE(SUM('TimePointBackgroundDetail'[Total CU (s)])),
"Throttling", CALCULATE(SUM('TimePointBackgroundDetail'[Throttling (s)])),
"% of Base Capacity", CALCULATE(SUM('TimePointBackgroundDetail'[% of Base Capacity]))
)
EVALUATE SELECTCOLUMNS(
varTable_Details,
"BillingType", [Billing type],
"Status", [Status],
"OperationStartTime", [OperationStartTime],
"OperationEndTime", [OperationEndTime],
"User", [User],
"Operation", [Operation],
"OperationID", [OperationId],
"WorkspaceName", [WorkspaceName],
"Item", [ItemKind],
"ItemName", [ItemName],
"TimepointCUs", [Timepoint CU (s)],
"DurationInS", [Duration (s)],
"TotalCUInS", [Total CU (s)],
"Throttling", [Throttling],
"PercentageOfBaseCapacity", [% of Base Capacity]
)'''
df_dax_result = fabric.evaluate_dax(
dataset,
dax_background_operation
)
if not df_dax_result.empty:
df_dax_result['capacityId'] = capacity_id
df_dax_result['Timepoint'] = timepoint_next
df_dax_result['OperationType'] = 'background'
#Set path and file name
subfolder = str(timepoint_next.date()) + '/'
file_name = timepoint_next.strftime("%H-%M-%S")
#Convert Fabric DataFrames into Spark DataFrames
df_dax_result_spark = spark.createDataFrame(df_dax_result, schema=dataframe_schema)
#Save DataFrames to OneLake
df_dax_result_spark.write.mode("overwrite").format("parquet").save(path_bronze + 'Background Operation/' + subfolder + file_name)
#Don't change timepoint intervals, as 30sec intervals are given
timepoint_next = timepoint_next + timedelta(seconds = 30)
i = i + 1
return iThe next cell is going through the same logic but for interactive operations. Therefore, I’m just providing the full code.
#Create a function to get Interactive Operations of the Metrics App
def generate_dax_interactive_operation(date_today, capacity_id):
"""
Generate the DAX statement which is used to get the interactive operations of the Metrics App for a given Capacity and day.
Arguments required:
date_today (datetime) - Date on which the interactive operation should be extracted
capacity_id (string) - Capacity ID on which the interactive operation should be extracted
Returns:
DAX Statement (Pandas DataFrame)
"""
#timepoint_start = date_today.replace(hour=0, minute=0, second=0, microsecond=0) #Set timepoint to the beginning of the day
timepoint_start = date_today.replace(day=24, month=4, year=2024, hour=9, minute=00, second=00, microsecond=00) #Use this timepoint to get a specific one - used for testing purpose
timepoint_next = timepoint_start
i = 0 #Initialising iteration count to check if all timepoints (2880 in total for a day) has been covered
#while timepoint_next.day == timepoint_start.day: #As long as the day of the next timepoint is the same as start timepoint, loop will continue and add 30seconds at the end
while timepoint_next <= datetime.strptime('24.04.2024 09:02:00', "%d.%m.%Y %H:%M:%S"): #Use this filter to get some specific timepoints only - used for testing purpose
current_year = str(timepoint_next.year)
current_month = str(timepoint_next.month)
current_day = str(timepoint_next.day)
starting_hour = str(timepoint_next.hour)
starting_minutes = str(timepoint_next.minute)
starting_seconds = str(timepoint_next.second)
dax_interactive_operation = '''
DEFINE
MPARAMETER 'CapacityID' = "''' + capacity_id + '''"
MPARAMETER 'TimePoint' = (DATE(''' + current_year + ''', ''' + current_month + ''', ''' + current_day + ''') + TIME(''' + starting_hour + ''', ''' + starting_minutes + ''', ''' + starting_seconds + '''))
VAR varFilter_Capacity = TREATAS({"''' + capacity_id + '''"}, 'Capacities'[capacityId])
VAR varFilter_TimePoint =
TREATAS(
{(DATE(''' + current_year + ''', ''' + current_month + ''', ''' + current_day + ''') + TIME(''' + starting_hour + ''', ''' + starting_minutes + ''', ''' + starting_seconds + '''))},
'TimePoints'[TimePoint]
)
VAR varTable_Details =
SUMMARIZECOLUMNS(
'TimePointInteractiveDetail'[OperationStartTime],
'TimePointInteractiveDetail'[OperationEndTime],
'TimePointInteractiveDetail'[Status],
'TimePointInteractiveDetail'[Operation],
'TimePointInteractiveDetail'[User],
'TimePointInteractiveDetail'[OperationId],
'TimePointInteractiveDetail'[Billing type],
'Items'[WorkspaceName],
'Items'[ItemKind],
'Items'[ItemName],
varFilter_Capacity,
varFilter_TimePoint,
"Timepoint CU (s)", SUM('TimePointInteractiveDetail'[Timepoint CU (s)]),
"Duration (s)", SUM('TimePointInteractiveDetail'[Duration (s)]),
"Total CU (s)", CALCULATE(SUM('TimePointInteractiveDetail'[Total CU (s)])),
"Throttling", CALCULATE(SUM('TimePointInteractiveDetail'[Throttling (s)])),
"% of Base Capacity", CALCULATE(SUM('TimePointInteractiveDetail'[% of Base Capacity]))
)
EVALUATE SELECTCOLUMNS(
varTable_Details,
"BillingType", [Billing type],
"Status", [Status],
"OperationStartTime", [OperationStartTime],
"OperationEndTime", [OperationEndTime],
"User", [User],
"Operation", [Operation],
"OperationID", [OperationId],
"WorkspaceName", [WorkspaceName],
"Item", [ItemKind],
"ItemName", [ItemName],
"TimepointCUs", [Timepoint CU (s)],
"DurationInS", [Duration (s)],
"TotalCUInS", [Total CU (s)],
"Throttling", [Throttling],
"PercentageOfBaseCapacity", [% of Base Capacity]
)'''
df_dax_result = fabric.evaluate_dax(
dataset,
dax_interactive_operation
)
if not df_dax_result.empty:
df_dax_result['capacityId'] = capacity_id
df_dax_result['Timepoint'] = timepoint_next
df_dax_result['OperationType'] = 'interactive'
#Set path and file name
subfolder = str(timepoint_next.date()) + '/'
file_name = timepoint_next.strftime("%H-%M-%S")
#Convert Fabric DataFrames into Spark DataFrames
df_dax_result_spark = spark.createDataFrame(df_dax_result, schema=dataframe_schema)
#Save DataFrames to OneLake
df_dax_result_spark.write.mode("overwrite").format("parquet").save(path_bronze + 'Interactive Operation/' + subfolder + file_name)
#print(i, timepoint_next, "interactive")
#Don't change timepoint intervals, as 30sec intervals are given
timepoint_next = timepoint_next + timedelta(seconds = 30)
i = i + 1
return iAfter the two functions have been created, they have to be called. This is what I do in my next piece of code. I also store the iteration number into a parameter which I can check if all timepoints have been extracted for the two different operation types.
#Get for each capacity background and interactive operations
for row in df_capacities.toLocalIterator():
capacity_id = row['capacityId']
i_background = generate_dax_background_operation(timepoint_start, capacity_id)
i_interactive = generate_dax_interactive_operation(timepoint_start, capacity_id)Once the data is extracted into separate files for each timepoint, I’m reading the whole folder for a day to combine all timepoint files into one and store the result into the silver layer.
#Set Subfolder and file name
subfolder = str(timepoint_start.date()) + '/'
file_name = str(timepoint_start.date())
#Read folder
df_background_bronze = spark.read.parquet(path_bronze + 'Background Operation/' + subfolder + '/*')
df_interactive_bronze = spark.read.parquet(path_bronze + 'Interactive Operation/' + subfolder + '/*')
#Save DataFrames to OneLake Silver layer
df_background_bronze.write.mode("overwrite").format("parquet").save(path_silver + 'Background Operation/' + file_name)
df_interactive_bronze.write.mode("overwrite").format("parquet").save(path_silver + 'Interactive Operation/' + file_name)Next, I read the data from the silver layer and combine the background and interactive operations into one file saving it into the Gold Layer.
#Read folder from Silver layer
df_background_silver = spark.read.parquet(path_silver + 'Background Operation/' + file_name)
df_interactive_silver = spark.read.parquet(path_silver + 'Interactive Operation/' + file_name)
#Combine background and interactive operations into one DataFrame
df_all_operations = df_background_silver.unionByName(df_interactive_silver)
#Save DataFrame into Gold Layer of OneLake
df_all_operations.write.mode("overwrite").format("delta").save(path_gold + file_name)Now, I just read the file from the Gold layer and save the result as table within my Lakehouse. This way I make sure Power BI can consume the data. Keep in mind, I’m appending the result to the table to make sure I’m not losing any history. If you run the code twice within a day, you will have duplicates in your Table!
df_all_operations_gold = spark.read.parquet(path_gold + file_name)
df_all_operations_gold.write.mode("append").format("delta").save('Tables/AllOperations')And that’s it! I extracted now the Metrics App data and stored it into my Lakehouse. Of course, I could create further Tables (e.g. Capacities), create a Semantic Model, and build a report on top!
Please let me know if this post was helpful and give me some feedback. Also feel free to contact me if you have any questions.
If you’re interested in the files used in this blog check out my GitHub repo https://github.com/PBI-Guy/blog